Mixture-of-Experts 기반 추천 시스템 - ①
Mixture-of-Experts (MoE)는 1991년 Jacobs 등이 처음 제한한 고전적인 앙상블 기법입니다.MoE는 모델 용량을 크게 확장할 수 있으며, 계산 오버헤드 가능성이 크지 않습니다. 이러한 능력은 최근 딥러닝 분
kmhana.tistory.com
에 이어서, 추천 시스템에서의 Mixture-of-Experts(MoE)를 소개 드리고자 합니다.
많은 추천 시스템(recommender system) 응용은 다중 작업 학습(Multi-task learning) 기반으로 구축됩니다. 이러한 접근법의 핵심 아이디어는 사용자 참여(user engagement), 사용자 만족(user satisfaction), 사용자 구매(user purchases) 등 여러 개의 관련 목표(objectives)를 함께 모델링하는 것입니다.
예를 들어:
- 사용자 참여(user engagement): 클릭 수(clicks), 체류 시간(engagement time) 등
- 사용자 만족(user satisfaction): 평점(ratings), 좋아요 비율(like rate) 등
- 사용자 구매(user purchases): 실제 구매 여부 등
추천 업계에서 MoE가 어떻게 활용되고 있는지에 대한 대표적인 사례들을 소개합니다.
※ https://blog.reachsumit.com/posts/2023/04/moe-for-recsys/
Mixture-of-Experts based Recommender Systems
The Mixture-of-Experts (MoE) is a classical ensemble learning technique originally proposed by Jacobs et. al1 in 1991. MoEs have the capability to substantially scale up the model capacity and only introduce small computation overhead. This ability combine
blog.reachsumit.com
를 기반으로 작성했습니다
여러 작업 간의 데이터 및 지식 공유(data & knowledge sharing)를 통해 보다 포괄적인 사용자 이해(holistic user view) 가 이루어집니다.
다중 작업 학습의 장점
- 데이터가 희소한(sparse) 작업에서도 효과적
다중 작업 학습은 데이터가 적은 작업에도 적용 가능합니다. 예를 들어, 특정 사용자 그룹에서 수집된 데이터가 적을 경우, 다른 관련 작업에서 학습된 정보를 공유하여 성능을 보완할 수 있습니다. - 정규화 역할을 수행(Regularization Effect) : 보조 작업(auxiliary tasks)의 학습 과정에서 발생하는 유도 편향(inductive bias) 이 주요 작업(Main task)의 일반화 성능을 향상시키는 정규화 효과를 가질 수 있습니다.
기존 다중 작업 학습 모델의 한계
일반적으로 널리 사용되는 다중 작업 학습 모델은 공유 하단(shared-bottom) 구조를 기반으로 합니다. 하지만 이러한 시스템은 다른 작업들이 동일한 파라미터를 공유해야 하기 때문에 최적화 충돌(Optimization Conflicts)이 발생할 가능성이 높습니다.
- 데이터 희소성(Data Sparsity): 일부 작업에 대한 데이터가 부족할 경우 성능 저하 발생
- 데이터 이질성(Data Heterogeneity): 서로 다른 유형의 데이터를 한 모델에서 학습하는 어려움
- 사용자 의도 복잡성(Complex User Intents): 사용자의 의도가 다양하고 복잡하여 단순한 모델로 학습하기 어려움
위에 한계점에도 불구하고, 최근에는 대규모 추천 시스템에서 MMoE(Multi-gate Mixture-of-Experts)를 활용한 다중 작업 학습(Multi-task Learning) 이 증가하고 있으며, 이를 통해 최첨단(State-of-the-art) 성능을 달성하고 있습니다.
다중 게이트 Mixture-of-Experts(MMoE)
Ma 등이 제안한 Multi-gate Mixture-of-Experts(MMoE)는 Mixture-of-Experts 구조를 다중 작업 학습(multi-task learning)에 맞게 발전시킨 모델입니다.
일반적으로 다중 작업 학습(multi-task learning)의 목표는 하나의 단일 모델을 이용하여 여러 가지 서로 다른 작업(task)을 동시에 학습하는 것입니다. 논문의 저자들은 이러한 다중 작업 학습이 각 작업 간 간섭에 민감(sensitive)할 수 있다고 가정했습니다.
이런 문제를 해결하기 위해 저자들은 MoE의 기본 구조를 다음과 같이 수정하였습니다.
- 전문가 네트워크(Expert Networks) 는 모든 작업들 간에 공유됩니다.
- 그러나 입력 데이터를 각 전문가에게 할당하는 게이팅 네트워크(gating networks) 는 Task별로 별도로 존재합니다. 즉, 각 작업마다 고유한 게이팅 네트워크를 가지고 있어서 작업 특성에 따라 최적의 전문가를 선택합니다.
- 추가로, 각 작업은 자신만의 최종 출력을 생성하는 작업 특화 타워(tower) 를 가지고 있어, 서로 다른 작업 간 최적화를 효과적으로 분리(decoupling)합니다.
저자들이 제안한 핵심 아이디어는 다음과 같습니다.
기존에 다중 작업 학습에서 자주 사용하는 공유된 하단 구조(shared-bottom, 모든 Task가 공통으로 단일 모델을 공유하는 구조)을 MoE 방식으로 바꾸는 것입니다. 즉, 모든 작업이 공통으로 활용할 수 있는 여러 전문가들이 존재하고, 각 작업은 자신만의 게이팅 네트워크를 통해 적합한 전문가만을 선택하도록 합니다.

Multi-gate MoE model 비교
이를 통해 각 작업의 학습 과정이 상호 간섭 없이 더욱 유연해지고, 개별 작업에 특화된 성능 최적화가 가능해집니다.
- 실험을 통해 저자들은 MMoE 아키텍처가 기존의 기본 베이스라인 방법들보다 성능이 우수하다는 것을 보여주었으며, 특히 작업 간 상관관계(correlation)가 낮을 때 더욱 뛰어난 성능을 보였습니다.
- Task 별 전문가 활용을 최적화하면서도, 불필요한 파라미터 증가를 방지하여 효율적인 학습을 가능하게 합니다.
구글의 대규모 추천 시스템에서도 이 MMoE를 테스트했으며, 이때는 사용자 참여(user engagement) 및 사용자 만족(user satisfaction)이라는 두 가지 목적에 최적화된 랭킹 모델을 학습시켰습니다. 하지만 각 작업별로 모델을 따로 학습하면 작업 수에 비례해 수십억 개의 파라미터를 학습해야 하므로, 저자들은 기존 shared-bottom 네트워크의 최상단(top layer)만 MMoE 레이어로 교체하는 방식으로 간단하게 적용했습니다. 즉, 최상단(top layer)의 MMoE 레이어 교체만으로도 효과가 있었습니다.
추천 시스템을 위한 Mixture-of-Experts(MMoE)
많은 추천 시스템 애플리케이션들은 멀티태스크 학습(Multi-task Learning)으로 구축되어 있습니다.
핵심 아이디어는 사용자 참여(예: 클릭, 체류 시간), 사용자 만족(예: 평점, 좋아요 비율), 사용자 구매 행동 등 여러 관련된 목표를 함께 모델링하여 사용자를 보다 포괄적으로 이해하려는 것입니다. 이러한 공동 모델링은 관련 작업 간 지식 및 데이터를 효율적이고 효과적으로 공유할 수 있게 해주며, 특히 데이터가 희소한 작업에 매우 유용합니다. 또한 멀티태스크 학습은 정규화 도구로도 작용하여, 보조 작업(auxiliary tasks)을 통해 유도되는 inductive bias(귀납 편향)가 주 작업(main task)의 일반화 성능을 향상시킬 수 있습니다.
가장 널리 사용되는 멀티태스크 학습 모델 중 하나는 shared-bottom 구조를 기반으로 합니다. 하지만 이 구조는 모든 작업이 동일한 파라미터를 공유하기 때문에 최적화 충돌 문제가 발생합니다. 이 외에도 데이터 희소성, 이질적인 데이터, 복잡한 사용자 의도 등도 멀티태스크 학습 시스템이 흔히 겪는 도전 과제입니다.
최근에는 일부 대규모 추천 시스템에서 MMoE(Multi-gate Mixture-of-Experts)를 활용하면서 SOTA(State-of-the-Art)를 달성하고 있습니다. 이 섹션에서는 실제 산업에서의 주목할 만한 사례들을 소개합니다.
Youtube의 영상 추천
[논문요약] DNN for YouTube(2016) - 추천 딥러닝 모델의 바이블
*크롬으로 보시는 걸 추천드립니다* https://static.googleusercontent.com/media/research.google.com/ko//pubs/archive/45530.pdf종합 : ⭐⭐⭐⭐1. 논문 중요도 : 5 점2. 실용성 : 4 점설명 : 추천 시스템에 적용된 딥러닝
kmhana.tistory.com
이전 논문 Youtube DNN의 연장선에 있는 논문입니다.
- 후보군 생성 (candidate generation): 수많은 동영상 중 수백 개 후보군 생성.
- 랭킹 단계 (ranking): 후보군에 대해 정교한 모델로 점수 매기고 정렬.
에서, 클릭, 시청 시간의 참여도(engagement)와 좋아요, 평가 등 만족도(satisfaction)의 Multi-task를 동시에 최적화하고자 합니다.
Multi-gate Mixture-of-Experts(MMoE)를 활용하여
- 각 사용자 행동(클릭, 좋아요 등)을 개별 목적 함수로 분리, 공유/비공유 파라미터를 조절하며 학습.
- 공유-bottom 구조 대신, 각 task에 gate network를 둬서 적절한 expert 선택.
- → 서로 다른 행동 간의 충돌 최소화하면서 효율적으로 학습 가능.
추천 시스템은 retrieval 단계에서 가져온 후보 동영상 리스트를 바탕으로,
- 후보 동영상 정보(candidate features)
- 사용자 정보(user features)
- 컨텍스트 정보(context features)
를 활용하여 두 가지 사용자 행동 범주(engagement, satisfaction)에 해당하는 확률을 예측하도록 학습합니다.
즉, 단일 모델이 사용자 참여도와 만족도를 동시에 고려해 다음 동영상을 추천하게 되는 구조입니다.
이전 모델에서 사용하던 shared-bottom 구조(Wide&Deep)의 마지막 레이어를 MoE 레이어로 교체했습니다.
이 MoE 레이어는 작업(task)별 게이팅(gating) 네트워크를 사용하며, 전문가들(experts)은 여러 작업 간에 공유됩니다.
다만, 입력(input) 레벨에서 바로 MoE를 적용하지는 않았는데, 그 이유는 입력 차원이 매우 높기 때문에 모델 학습 및 서빙 비용이 크게 증가하기 때문입니다. 따라서 입력에 직접 적용하기보다는 공통 레이어 마지막 단계에만 MoE를 배치하는 방식으로 효율성을 고려했습니다.
또한 논문에서는 선택 편향(selection bias)을 줄이기 위해, 이 MMoE와 함께 얕은(shallow) 타워(tower)를 추가로 학습시켰습니다. 이는 특정 동영상이 자주 노출되는 편향을 보정하려는 목적입니다.
Gmail의 Mixture of Sequential Experts (MoSE)
Google은 MoSE(Mixture-of-Sequential-Experts)를 제안했습니다. Sequential 데이터(예: 검색 기록이나 탐색 로그 등 사용자 행동의 시간 흐름)에 초점을 맞춘 멀티태스크 모델링로서, 사용자 행동을 더 잘 예측하는 것이 목표입니다.
MMoE 구조에 시간적 의존성(temporal dependencies)을 반영하기 위해 다음과 같은 구성 요소들을 사용했습니다:
- LSTM 기반의 shared-bottom 레이어
- LSTM 기반의 experts (전문가 네트워크)
- LSTM 기반의 task-specific towers (작업별 타워)
즉, 전체 구조가 LSTM을 중심으로 구성되어 있어, 시간에 따른 사용자 행동의 패턴을 학습할 수 있으며, LSTM의 시계열 처리 능력과 MMoE의 유연한 전문가 선택 구조를 결합한 모델입니다. 이를 통해 Gmail과 같은 서비스에서 사용자 행동을 보다 정밀하게 예측할 수 있게 됩니다.
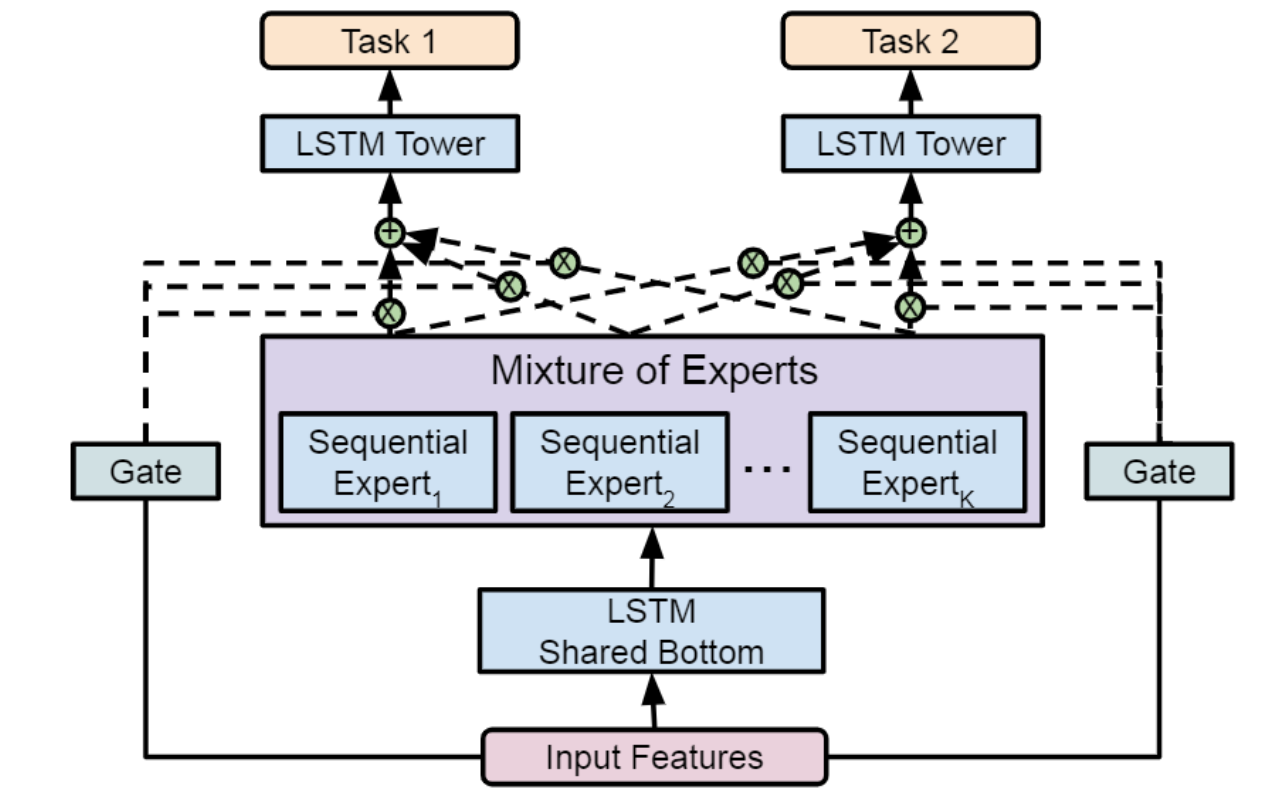
Youtube MMoE와 다르게 Input Feature와 Gate가 연결되어 있습니다.
실험 결과에 따르면, LSTM 기반의 MMoE(MoSE) 모델은 FFN(Feed-Forward Network) 기반의 MMoE 모델보다 사용자 활동 스트림(user activity streams) 경향을 더 효과적으로 예측했습니다. 즉, 시계열 데이터를 처리할 수 있는 LSTM 구조가 정적 특징만 처리하는 기존 구조(FFN)보다 더 사용자 행동의 시간적 흐름과 패턴을 더 잘 포착했다는 의미입니다.
이는 특히 Gmail처럼 사용자 행동이 시간에 따라 축적되는 환경에서 큰 장점이 됩니다.
POSO(Personalized Cold Start Modules) - Kwai 추천 시스템
Kwai 앱에 사용된 추천 시스템 구조 POSO(Personalized Cold Start Modules) 논문에서 설명했습니다. 이 시스템은 개인화된 콜드 스타트 추천을 목표로 하며, 다음과 같은 입력 특징들을 사용합니다. sequential 및 non-sequential 특징 모두를 사용합니다.
- 순차적 특징(sequential features): 예) 사용자의 과거 상호작용 기록
- 비순차적 특징(non-sequential features): 예) 사용자 ID, 정적 프로필 정보 등
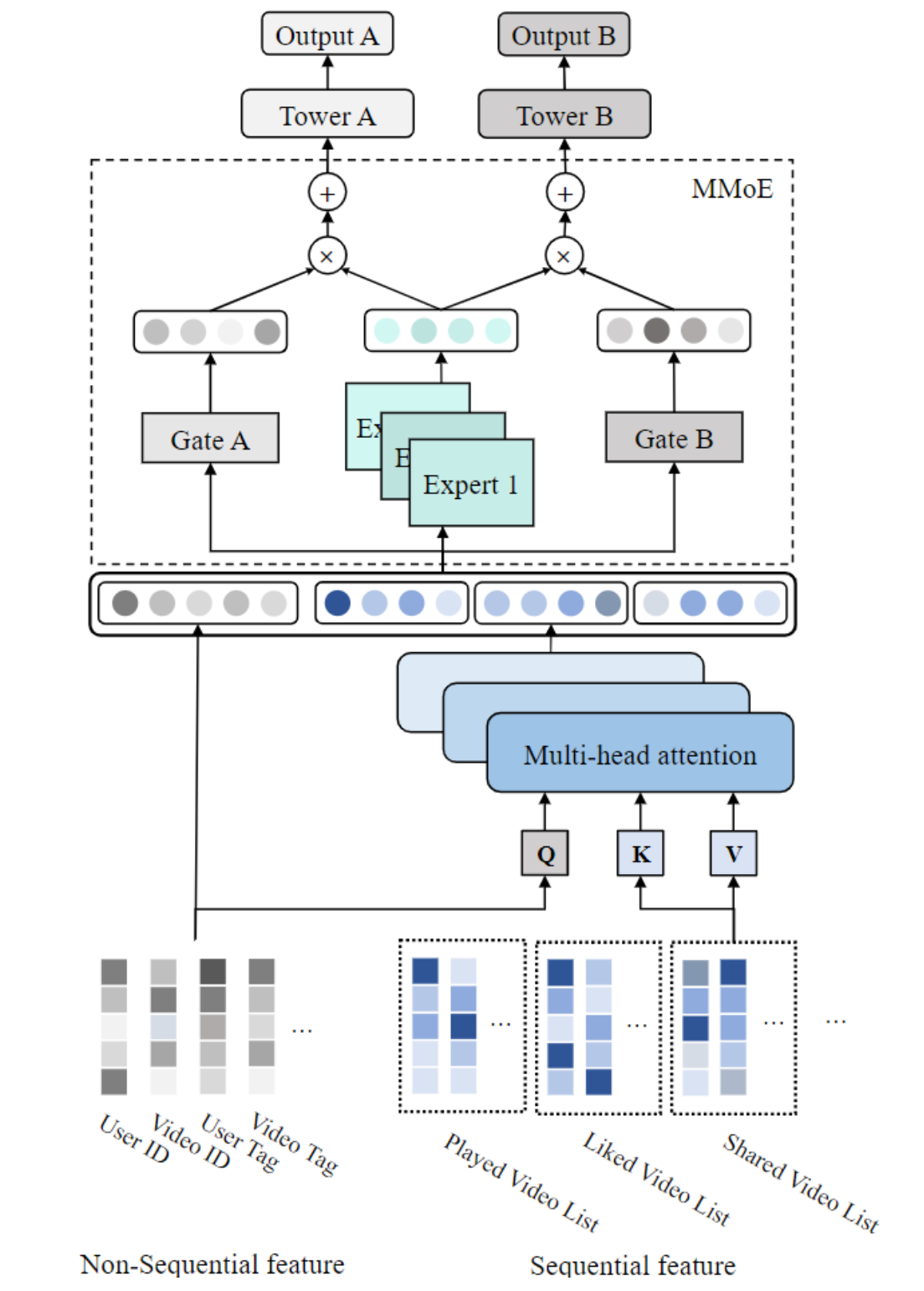
- 임베딩 변환
모든 특징들은 먼저 임베딩 룩업 테이블을 통해 저차원 벡터로 매핑됩니다. - Multi-Head Attention (MHA)
Transformer 구조로서 각 순차적 특징에 대해 MHA 모듈을 적용하여, 각 attention head에서 나온 벡터들을 결합합니다.
→ 이 과정을 통해 사용자 행동의 시계열 정보를 정교하게 통합합니다. - 벡터 결합 및 MMoE 적용
순차적 벡터와 비순차적 벡터를 하나로 합친 후, MMoE(Multi-gate Mixture-of-Experts) 레이어에 입력합니다. - 태스크별 MLP
MMoE 출력을 작업(task)별 MLP에 전달하여,
각 작업(예: 클릭 예측, 구매 확률 등)에 맞는 사용자 행동 확률을 예측합니다.
이 구조는 콜드 스타트 사용자에게도 개인화된 추천을 제공할 수 있도록 설계되었으며,
시계열과 정적 정보의 통합, MMoE의 유연한 태스크 분리, Multi-Head Attention (MHA)를 통한 표현력 향상이 핵심 포인트입니다.
결론
Mixture-of-Experts(MoE)는 다양한 산업 분야에서 널리 사용되는 구조로, sub-tasks로 나눈 뒤 각각을 전문가 네트워크가 처리하는 방식입니다. 게이팅 네트워크는 각 입력에 대해 어떤 전문가를 사용할지 선택하여 계산 자원을 절약합니다.
MoE의 주요 장점은 다음과 같습니다:
- Shared information와 task-specific information을유연하게 분리하여 모델링 가능
- 조건부 계산(Conditional Computation) 방식으로 입력마다 필요한 부분만 활성화되어 효율적
- 학습과 추론 단계 모두 병렬 처리에 유리
- 대규모 시스템에서 빠르고 확장성 높은 성능 구현 가능
MoE의 개념과 주요 변형 구조들을 소개했으며, YouTube, Gmail, Kuaishou(Kwai) 등의 실제 추천 시스템 사례를 통해 산업 현장에서의 활용 방식을 설명했습니다.
https://reachsumit.com/#experience
https://reachsumit.com/#experience
Who am I? My name is Sumit Kumar. I have over 10 years of software development and machine learning, AI research work experience in the tech industry. I am currently working as a Senior Machine Learning Engineer at Meta. My main focus at work is on search,
reachsumit.com
에는 좋은 추천 및 Multi-Task 자료들이 정리되어 있어, 추천드립니다!
'발전중인 AI > 추천(Recommendation)' 카테고리의 다른 글
| Mixture-of-Experts 추천 시스템 개요 - ① (1) | 2025.03.14 |
|---|---|
| [논문요약] GDCN(Gated Deep Cross Net, 2023) - 추천 AI의 핵심 트렌드 (0) | 2025.02.03 |
| [논문요약] DNN for YouTube(2016) - 추천 딥러닝 모델의 바이블 (0) | 2022.02.15 |
| [논문요약] 딥러닝 관련 추천 모델 - Survey(2019) (0) | 2022.02.15 |
| 추천 시스템 기본 - 협업 필터링(Collaborative Filtering) - ② (0) | 2021.08.10 |