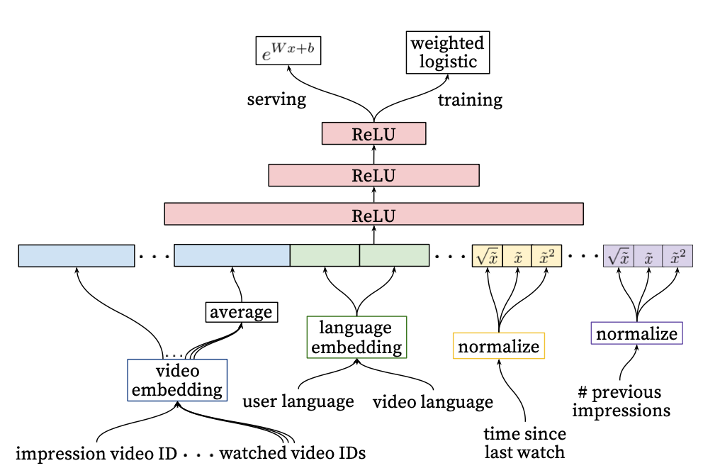
Mixture-of-Experts (MoE)는 1991년 Jacobs 등이 처음 제한한 고전적인 앙상블 기법입니다.MoE는 모델 용량을 크게 확장할 수 있으며, 계산 오버헤드 가능성이 크지 않습니다. 이러한 능력은 최근 딥러닝 분야에서 혁신적으로 결합되어, 다양한 분야에서 MoE를 광범위하게 사용하게 되었습니다. 특히, LLM(Large Language Model)와 같은 대규모 어플리케이션에 성공적으로 활용되고 있습니다. Mixture-of-Experts (MoE)에 대한 소개와 중요하게 개선된 히스토리를 소개하고자 합니다. ※ https://blog.reachsumit.com/posts/2023/04/moe-for-recsys/ Mixture-of-Experts based Recommender Sys..