*크롬으로 보시는 걸 추천드립니다*
우리 일상생활에 녹아있는 "인공지능(AI)"에는 추천 시스템이 있다는 것을 소개해 드렸습니다
Have A Nice AI
kmhana.tistory.com
이제 부터는 조금 더 알고리즘 측면에서, 추천이 이루어지고 있는지 차근차근 뜯어 보겠습니다
가장 추천 알고리즘의 기본은
1) 협업 필터링(Collaborative Filtering)
• Memory Based Approach
- User-based Filtering
- Item-based Filtering
• Model Based Approach
- 행렬 분해(Matrix Factorization)
2) 콘텐츠 필터링(Contents-Based Filtering)
가 있습니다.
이번 파트에서는 "협업 필터링(Collaborative Filtering) - Memory Based" 부터 소개해 드리겠습니다!
(* 언제든지 부족한 부분 알려주시면 반영하겠습니다 ㅎㅎ 함께 공부해 나아가봐요)
협업 필터링 이란 ?
영화를 추천받고 싶을때 우리는 어떻게 할까요?
1. 내가 좋아하는 감독, 장르, 키워드의 영화를 찾아본다
2. 나랑 성향이 비슷한 친구들이 본 영화를 찾아본다
가 대표적인 방법일 것입니다.
이 것은
1. 내가 좋아하는 감독, 장르, 키워드의 영화를 찾아본다
▶ Content Based Filtering
2. 나랑 성향이 비슷한 친구들이 본 영화를 찾아본다
▶ 협업 필터링(Collaborative Filetering)
라고 할 수 있습니다!
○ 협업 필터링(Collaborative Filtering) 특징
• 가정 : 나와 비슷한 취향의 사람들이 좋아하는 것은 나도 좋아할 가능성이 높다
→ 많은 사용자로 부터 얻은 취향 정보를 활용
• 핵심 포인트 : "많은 사용자들"로 부터 얻은 취향 정보를 활용
- 사용자의 취향 정보 = 집단 지성
- 축적된 사용자들의 집단 지성을 기반으로 추천
- 예를 들어 : A 상품을 구매한 사용자가, 함께 구매한 다른 상품들
협업 필터링 종류
○ 협업 필터링(Collaborative Filtering) 대표 접근법

1) Memory-Based Approach
• 유사한 사용자(Users)나 아이템(Item)을 사용
- 특징 : 최적화 방법이나, 매개변수를 학습하지 않음. 단순한 산술 연산만 사용
- 방법 : Cosine Similarity나 Pearson Correlation을 사용함, ( * KNN 방법도 포함됨)
- 장점 : 1. 쉽게 만들 수 있음
2. 결과의 설명력이 좋음
3. 도메인에 의존적이지 않음
- 단점 : 1. 데이터가 축적 X or Sparse한 경우 성능이 낮음
2. 확장가능성이 낮음 ( ∵ 데이터가 너무 많아지면, 속도가 저하됨)
2) Model-Based Approach
• 기계학습을 통해 추천
- 특징 : 최적화 방법이나, 매개변수를 학습
- 방법 : 행렬분해(Matrix Factorization), SVD, 신경망
- 장점 : 1. Sparse한 데이터도 처리 가능
- 단점 : 1. 결과의 설명력이 낮음
Memory-Based Approach 협업 필터링
○ Memory-Based Approach의 대표 방법론

• 대표 방법론 1) User-based Filtering 2) Item-based Filtering
• User-based Filtering
- 특정 사용자(User)를 선택
- 예시 : SNS에서의 친구 추천 서비스
1. "평점 유사도"를 기반으로 나와 유사한 사용자(Users)들을 찾음
2. 유사한 사용자가 좋아한 Item을 추천
→ 해석 : 당신과 비슷한 사용자 "ㄱ"은, "B"영화도 좋아했습니다
• Item-based Filtering
- 특정 아이템(Item)을 선택
- 예시 : 함께 구매한 경우가 많은 상품 - '사이다'와 '콜라'
1. 특정 Item을 좋아한 사용자들을 찾음
2. 그 사용자들이 공통적으로 좋아했던 다른 Item을 찾음
→ 해석 : 이 아이템을 좋아한 사용자는, "B"영화도 좋아했습니다
○ 유사도 측정 방법
• 두 방법 모두 유사도(거리)를 측정하여 사용함
• 거리 측정 방법은 다양함
- 사용자(행) - 아이템(열) 행렬을 사용함
• 일반적인 거리 측정 방법론
- Cosine Similarity
- Pearson Similarity
- Euclidean Distance
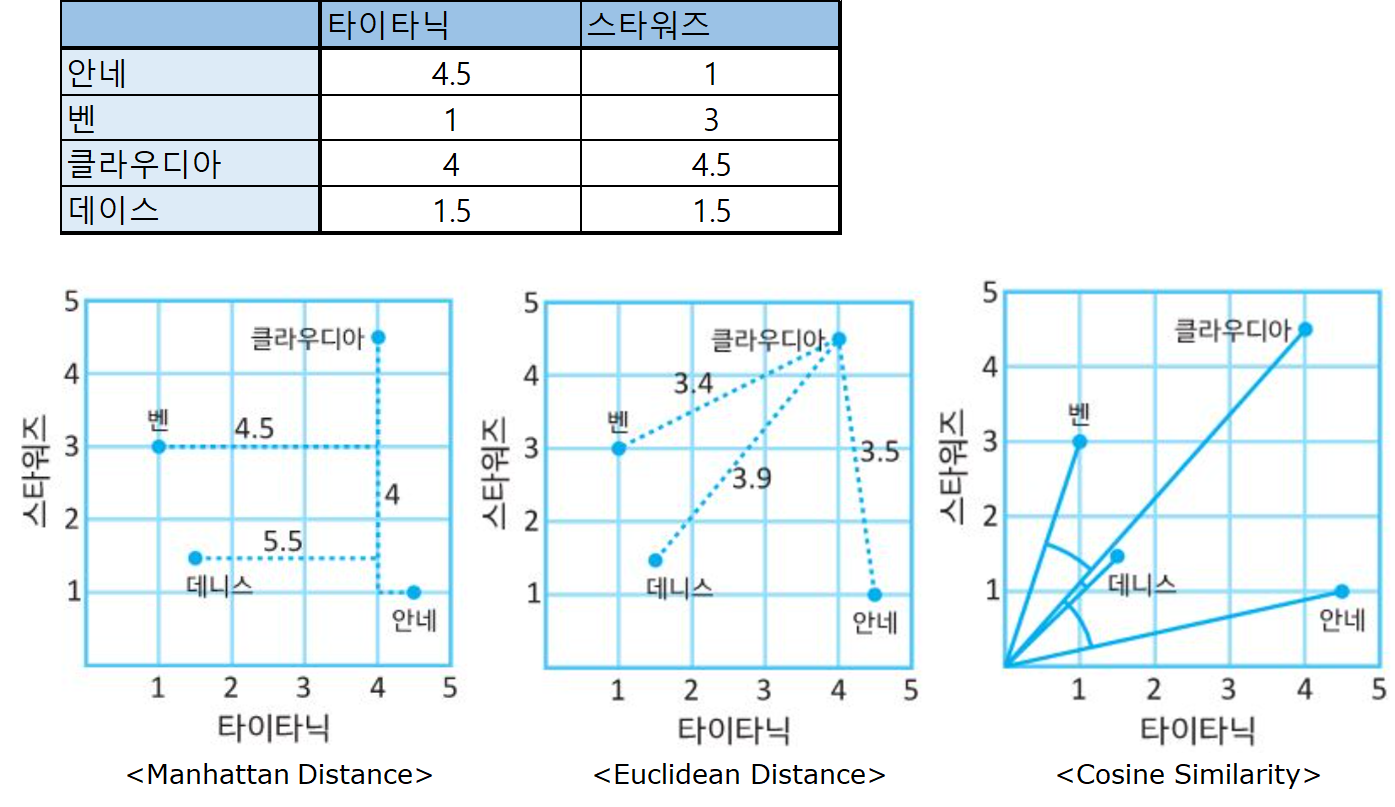
• Cosine Similarity
$$ sim(u, u') = cos(\theta) = \frac{R_{u} \cdot R_{u'}}{\left \| R_{u} \right \|\left \| R_{u'} \right \|} = \frac{\sum_{i=1}^{n}R_{ui}\times R_{u'i}}{\sqrt{\sum_{i=1}^{n}(R_{ui})^{2}} \times \sqrt{\sum_{i=1}^{n}(R_{u'i})^{2}}} $$
- 사용자 \(u\)와 사용자 \(u'\)가 같은 방향성을 보고 있지는를 평가함
- 일반적으로 사용되는 유사도
• Pearson Correlation Similarity
$$ sim(u, u') = \frac{\sum_{i=1}^{n}(R_{ui} - \bar{R_{u}})( R_{u'i} -\bar{R_{u'}} ) }{\sqrt{\sum_{i=1}^{n}(R_{ui} - \bar{R_{u}})^{2}} \times \sqrt{\sum_{i=1}^{n}(R_{u'i} - \bar{R_{u'}})^{2}}} $$
- 평균적인 경향성에서 얼마나 차이가 나는지를 기반으로 함
- Centered Cosine Similarity 라고도 함
- 평균을 빼므로, 사용자 \(u\)와 사용자 \(u'\)가 함께 사용한 아이템이 꽤나 있어야 함
○ 유사도를 활용한 추천 Flow
• "유사도를 계산한 후 우리는 어떻게 아이템(Item)을 추천할 수 있을까?"에 대한 설명 드립니다
https://medium.com/@toprak.mhmt/collaborative-filtering-3ceb89080ade
Collaborative Filtering
In this blog, I’ll be covering a recommender system technique called collaborative filtering. So let’s get started. Collaborative…
medium.com
- 위에 사이트를 참고했습니다
• User Based Fitering을 기준으로 설명 드립니다. Item Based와의 차이는 유사도(Similarity) 측정에서만 차이가 남
1) User-Item 행렬(Matrix)를 구축

- 목표 : 4번째 사용자(User)에게 영화를 추천해주기 위해서, 4번째 사용자가 아직 보지 않은 영화의 평점을 예측
2) User간의 유사도 계산

* 유사도 값에 대한 예시는 대략적인 값으로 정확하지 않습니다
3) 예상 아이템의 평점 추론
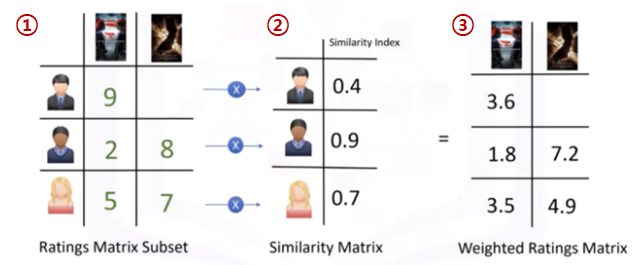

- ① 4번째 사용자가 보지 않은 영화들을 본 사용자의 평점을 추출
- ② 4번째 사용자와의 "유사도" 계산
- ③ 각 사용자 별 "유사도 x 평점" 계산
$$ sim(u,u') \times R_{u'i} $$
- ④ 유사도가 반영된 "가중치 평점을 합산"
$$ \sum_{u'}sim(u,u') \times R_{u'i} $$
- ⑤ 가중치를 나누어 "평균 평점"을 계산하여, 4번째 사용자의 보지 않은 영화의 평점을 추론
$$ \hat{R_{ui}} = \frac{\sum_{u'}sim(u,u') \times R_{u'i}}{\sum_{u'}\left | sim(u,u') \right | } $$
○ Memory-based Approach의 장단점
• 장점
- 최적화(Optimization)나 훈련(Train)이 필요 없음
- 쉬운 접근 방식
• 단점
- 희소(Sparse)데이터 경우 성능 저하 ( ∵ 비교 대상이 적으면, 성능저하)
- 확장성에 제한 ( ∵ 비교 대상이 많아지면, 계산량이 증가)
마치며
○ Part1 에서 다룬 추천 시스템
• 협업 필터링(Collaborative Filtiering)의 종류와 그 중 대표 접근법 Memory-Based 을 알아봤습니다
- 유사도 측정 방법
- User Based Filtering
- Item Based Filtering
앞으로 "협업 필터링 Part2" 에서는
○ Part2 에서 다룰 예정인 추천 시스템
• 협업 필터링(Collaborative Filtiering)의 대표 접근법 Model-Based 을 알아볼 예정입니다
- Matrix Factorization(행렬 분해)
- Neural Network(신경망)
• 협업 필터링(Collaborative Filtiering)의 한계
• 그 밖의 방법론 소개
다룰 예정입니다!
'발전중인 AI > 추천(Recommendation)' 카테고리의 다른 글
| [논문요약] GDCN(Gated Deep Cross Net, 2023) - 추천 AI의 핵심 트렌드 (0) | 2025.02.03 |
|---|---|
| [논문요약] DNN for YouTube(2016) - 추천 딥러닝 모델의 바이블 (0) | 2022.02.15 |
| [논문요약] 딥러닝 관련 추천 모델 - Survey(2019) (0) | 2022.02.15 |
| 추천 시스템 기본 - 협업 필터링(Collaborative Filtering) - ② (0) | 2021.08.10 |
| 추천 시스템(Recommendation System) 시작 (0) | 2021.08.07 |