Google Brain팀에서 발표한
Big Transfer (Bit) : General Visual Representation Learning 논문에 대해서 소개하고자 합니다.
종합 : ⭐⭐⭐
1. 논문 중요도 : 4점
2. 실용성 : 3점
설명 : Transfer Learning에 인사이트를 줌
- 대용량 데이터를 사전학습 할 때와 그 모델을 Fine-tuning할때에 대한 고찰
- Transfer Learning에 좋은 참고가 될 수 있다
- 단, Google 전용 데이터를 사용했으며, 엄청난 자원이 필요하다는 점은 큰 단점이다.
Big Transfer (BiT) 의의
1. '어떻게 해야 Transfer Learning을 잘 할 수 있을까?'에 대한 Insight를 얻을 수 있다.
2. 게다가, imagenet에서, 2019년도에 1등을 기록했기 때문에 읽어볼 가치가 높다.

Transfer Learning의 목적은
'잘 만든 Pre-Trained(사전 학습) 모델하나, 여러 모델 안부럽다!'입니다.
사전학습만 잘 해두면, 여러 DownStream Task에 활용할 수 있기 때문입니다.
BiT 요약
BiT는 두 가지 관점(Upstream, Down Stream)으로 나누어서 논문을 진행하고 있습니다.
1. Upstream Pre-Training
1) 데이터 수, 모델의 크기, 계산량(Training time)간의 연관성을 파악
2) Group Normalization(GP) + Weight Standardization(WS)의 중요성
- Small, Big Batch size 모두에서 좋은 성능을 보인다. (Batch size에 중요성에 대해서 이야기 해주고 있다.)
- 기존의 Batch Normalization은 안정적인 학습에 도움이 되었으나,
But, 1. 분산처리하는 GPU 장치간의 효율성이 저하 됨
2. Transfer에 안 좋은 영향( ∵ BN은 통계량을 업데이트 하므로)
2. Transfer to Dowstream
1) One Hyper-parameter Search - 휴리스틱 Rule(저자는 이것을 BiT-HyperRule라고 명칭)
- Transfer를 진행할 때 필요한 fine-tuning 시에 필요한 Hyper-Paramter를 줄여서,
간편하게 Downstream Task를 해결하고자 했다.
- Hyper-parameter 휴리스틱하게 결정했지만, Transfer 실용시에 많은 참고가 될수 있을 거 같다.
- 이미지 해상도와 데이터셋 크기를 통해, 학습 스케줄과 Mixup 사용여부를 결정한다.
2) Task 마다의 Data Augmentation이 다름
- 예 : object orientationr Task 같은경우 Flip이나 Crop이 악영향을 줌
3) Training과 Test에서 발생되는 해상도 차이 해결
- Fine-Tuning 단계에서 해결
4) Transfer 진행 시, weight decay나 Dropout 같은 Regularization 사용 X
- 매우 큰 모델 + 매우 작은 데이터의 Downstream Task에서도, 저런 Regularization을 사용하지 않아도 좋은 성능
HyperRule 및 모델구성 설명
BiT가 제안한 HyperRule이 사실 이 논문에 핵심입니다.
1. Upstream Pre-Training
- 모델 Architecture: ResNet-v2
- 모델 크기(디폴트) : ResNet 152x4d
- Optimizer : SGD with momentum ( Lr = 0.03, m = 0.9)
* Adaptive 계열을 써도 더 좋은 성능계선은 없었다.
- 학습 데이터 : BiT-S - 130만 장( ILSVRC-2012) / BiT-M - 1400만 장(ImageNet-21k) /
BiT-L - 3억 장( JFT)
※ JFT dataset : 여기서 부터 자본주의의 중요성이 나온다. 구글이 만든 dataset이고 오픈되지 않았다.
개인적인 견해로, 형평성 관점에서 SOTA에서 JFT dataset 사용 여부를 분리하는게 좋을것같다.
Google 팀에서, JFT dataset을 활용하여, 엄청난 성과를 보이고 있다.
- 이미지 크기 : 224x224
- Train Schedule : BiT-S와 BiT-M - 90 epochs(30,60, 80에서 Lr decay 10)
BiT-L - 40 epochs(10, 23, 30, 37에서 Lr decay 10)
- Warm-up : 5000 steps (매 스탭마다 batch size / 256 씩 곱한다.)
※ Warm-up은 요즘 CNN에서 필수 덕목처럼 보인다.
- Batch Size : 4096 - 엄청난 숫자이며.. 사용한 TPU는 512 장 (chip 당 8 이미지 학습)
※ 실무의 입장에서, 함부로 사용할 수 없는 자원 규모이다.
- weight decay : 0.0001 ( Transfer learning에서는 사용하지 않는다)
2. Downstream Fine-Tuning
* 기준 : 2만 장 - Small task / 50만 장 미만 - Medium task / 50만 장 이상 - Large task라고 정의
- Optimizer : SGD with momentum ( Lr = 0.003, m = 0.9) → 사전 학습보다 0.1 낮음
- Batch Size : 512
- 이미지 크기 : 96x96↓ ▶ 160x160변환 ▶ 128 crop
448x448↑ ▶ 384 crop
- Fine-Tuning Schedule : 공통 - 30, 60, 90%에서 Lr decay (10 factor)
S task - 500 steps (최소 약 12.8 epoch)
M task - 1만 steps (최소 약 10.2 epoch)
L task - 2만 steps (최대 20.5 epoch)
- Mixup 유무 : M과 L task에서만 Mixup 사용(alpha = 0.1)
실험 세팅은 참고정도만 하자!

* 위에의 실험세팅을 통해, HyperRule을 제안했다.
BiT 결과
결과는 매우 뛰어났다!
덜 중요한 결과그림은 본 리뷰에서 더보기 처리하거나 생략하고자한다.(당연히 좋다고 할테니)
1. Transfer 결과 매우 적은 데이터만으로도 엄청난 성능을 보였다.
2. Semi-Supervised Learning 보다 더 좋은 성능
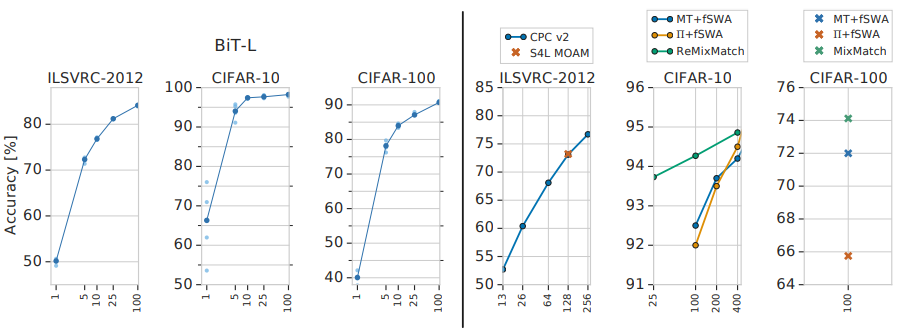
3. Classification 뿐만아니라 여러 Task(Object Detection 등)에서도 좋은 성능을 보임
BiT 결과 분석
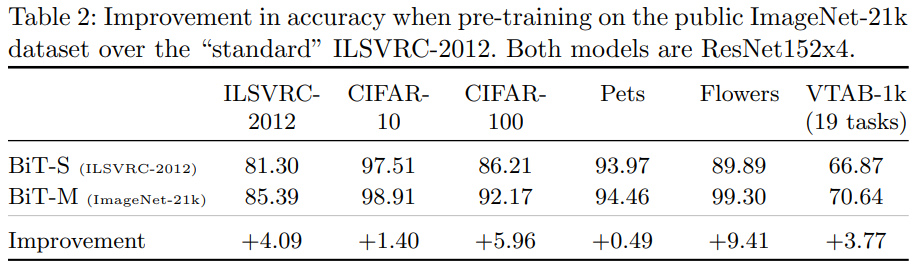
1) 사전학습시, 데이터 증가의 효가는 뛰어나다.

* X축 : Upstream 데이터 사이즈 / Y축 : 정확도 / 원의 크기 : Capacity
1. 작은데이터를 쓰는데, 큰 모델을 사용하면 역효과가 날 수 있다.( ILSVRC-2012 dataset은 이제 작은 데이터 셋..)
2. 작은 모델을 쓰는데, 큰 데이터 셋도 좋지 않다.( ResNet-50x1은 작은 모델..)
3. 큰 데이터 + 큰 모델을 사용 → Downstream에서도 뛰어난 성능을 보인다.
2) 큰 데이터를 학습 시키기 위해선, 큰 학습 자원이 필요하다
1. 큰 데이터를 학습키 위해선, 더 긴 시간 학습 해야한다. ← 그렇지 않다면, 오히려 성능이 저하된다.
2. 학습시, 주(Week) 단위에서는 성능향상이 되지 않는것 처럼 보이지만, 개월(Month)단위로 보면 증가 중이다.
3. 높은 Weight Decay 학습 시 : 더 빠르게 수렴하나, 최종적으로 더 낮은 성능으로 수렴
낮은 Weight Decay 학습 시 : 수렴은 느리나, 최종적으로 더 좋은 성능으로 수렴
3) Large Batches, Group Normalization, Weight Standardization
1. 모델의 Capacity가 커서, 하나의 GPU chip당 작은 Mini-Batch가 할당 되어 BN의 단점이 부각됨
2. Group Normalization와 Weight Standardization를 같이 썼을 때, Up/Downstream에서 좋은 성능
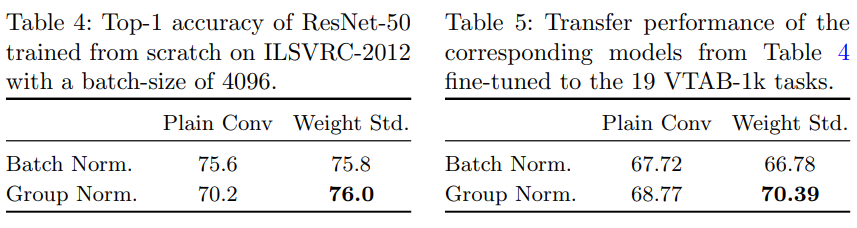
* Table 4 : 사전 학습시 성능
* Table 5 : Transfer시 성능
Group Normalization, Weight Standardization에 대해선 간단하게 소개하고자한다.

※ Group Normalization : Batch Norm의 mini-batch 사이즈가 작아질 수록 성능이 저하되는 단점을 보안

※ Weight Standardization : Mini-batch와 관련없이, Weight 행렬을 표준화
→ Optimzation landscape를 Smooth하게 만듬
기존의 Batch Nomalization은, internal covariate shift를 줄임으로써 성능향상에 크게 기여한다고 알려져왔다.

하지만, arxiv.org/pdf/1805.11604.pdf 저자는 covariate shift 보다는 Optimzation landscape를 Smooth하게 만들기 때문에, 좋은 효과가 있는 것이라고 설명한다.

Weight standardization에 관한 좀 더 자세한 사항은, Lunit의 blog에서 참고해도 좋다!
BiT 총평
1. 엄청난 양의 데이터, 학습자원이 중요하다.
작은 기업과 글로벌 회사간의 격차는 점점 더 빠른속도로 벌어진다 - 국내 대기업에서도 벅차보인다.
2. 그럼에도, 우리는 Transfer Learning에 대한 Insight를 얻을 수 있다.
- 필요한 hyperparameter가 무엇인지, 그 조합은 어떻게 구성하는 지 등등..
'딥러닝을 위한 > SOTA(State-of-the-Art)' 카테고리의 다른 글
| [논문요약] Semi-superviesd의 정수 - Meta Pseudo Labels(2021) (2) | 2022.01.01 |
|---|---|
| [논문요약] Vision분야에서 드디어 Transformer가 등장 - ViT : Vision Transformer(2020) (9) | 2021.07.05 |
| [논문요약] 효율적인 Architecture - EfficientNet(2019) (1) | 2021.04.14 |