*크롬으로 보시는 걸 추천드립니다*
https://arxiv.org/pdf/2003.10580v4.pdf
종합 : ⭐⭐⭐⭐
1. 논문 중요도 : 5 점
2. 실용성 : 4 점
설명 : Semi-supervised Learning으로도 엄청난 성능을 기록한 훌륭한 방법론
- 학생을 가르치는 선생과, 그 선생님을 발전시키는 학생
- Semi-Supervised Learning의 가능성을 여김 없이 보여준 논문
- 엄청난 모델 크기를 자랑하고 있는 Transformer 계열 모델 사이에서, 상대적으로 매우 작은 모델로 고성능 기록!
- Noisy Student 논문을 함께 읽은 효과는 보너스
( * 개인적인 의견이며, 제 리뷰를 보시는 분들에 도움드리기 위한 참고 정도로 봐주세요)

2020년 처음 ImageNet Top-1 Accuracy 90.0%의 벽을 깬 모델 및 논문이 등장했었습니다!
2019년 EfficientNet와
2020년대 Vision 분야에서 처음으로 Trasformer가 도입된 ViT 이후로,
SOTA를 위에 두 방법이 양분했습니다
위에 두 방식 이외에 또 다른 ImageNet Top-1 Accuracy에서 SOTA를 달성했던 방법이 있는데요.
- 바로, Semi-supervised Learning을 적용한 Noisy Student가 대표적입니다
"Meta Pseudo Labels"는 EfficientNet을 기본으로 사용하고 있지만,
Noisy Student 방법처럼 Semi-supervised Learning 방식을 차용하고 있습니다

- 최근 SOTA를 찍고 있는 모델들의 형태를 보면
"Meta Pseudo Labels"의 의미가 단순히 성능에 국한되어 있지 않다는 것을 알 수 있습니다.
- 1위부터 4위까지 Transformer 방식에 모델들의 Parameter는 1000M쯤은 가볍게 넘는 모습을 보여줍니다.
- 반면, "Meta Pseudo Labels"은 480M parameter로 상대적으로 작은(?) 모델 크기를 보여줍니다
- 어떻게 상대적으로 작은(?) 모델로 SOTA를 달성할 수 있었는지 알아볼 필요가 있어 리뷰를 하게 되었습니다
Meta Pseudo Labels 소개
- Pseudo Labels란?
- 이전 SOTA였던, Noisy Student Model의 핵심 아이디어
1. Teacher는 Labeled data를 학습
2. 학습한 Teacher로 Unlabeled data에서의 Pseudo Label 생성
( * Pseudo Label 이란? 모델이 추론 Softmax를 Label로 썼다고 생각하시면 됩니다)
3. Labeled data와 Pseudo Label가 생성된 Unlabeled data을 결합
4. Child Model을 학습

- 데이터의 풍부함과 data augmentation 덕분에 더 좋은 성능을 가진, Student Model이 만들어짐
- 심지어, 선생님보다 뛰어남
- 기존의 Pseudo Labels 단점
- Teacher가 부정확한 경우 → Pseudo label 부정확 → Student는 잘 못된 Pseudo label을 학습
- 확증 편향(confirmation bias) 발생
Meta Pseudo Labels 의의
1. 확증 편향(confirmation bias)을 보완
- pseudo label이 student에게 미치는 영향을 관찰
- 학생의 피드백을 활용(feedback from the student) → teacher to generate better pseudo labels
- feedback signal : student model의 labeled dataset에 대한 성능
- feedback signal = reward to train the teacher
- student 학습 과정에서 Teacher도 지속적으로 업데이트
2. Semi-Supervised Learning 방법으로 SOTA를 기록
- Teacher Network → Unlabeled data에서 Pseudo Label을 생성
- Student Network → Unlabeled data에서 Pseudo Label로 학습

3. 기존의 Pseudo Label과의 차이점 :
- 기존 : Teacher Network는 고정
- 제안 방법 : Student Network가 Labeled Dataset에서의 성능을 활용하여, Teacher Network을 피드백
▶ Teacher가 더 좋은 Pseudo Label을 생성할 수 있도록, Teacher가 지속적으로 조정됨

즉, 학생만 선생님을 통해서 배우는 것이 아니라, 선생님도 학생을 통해서 배움
4. Meta Pseudo Labels 학습의 효율성 :
- Bit-L과 ViT 모두 JFT의 3억 개의 레이블이 지정된 이미지에 대해 사전 학습
- 레이블이 없는 이미지만 사용함!
Meta Pseudo Labels 설명
( ※ 주의 : 해당 파트는 최적화에 대한 설명이라, 어려우신 분들은 넘어가셔도 괜찮습니다! )
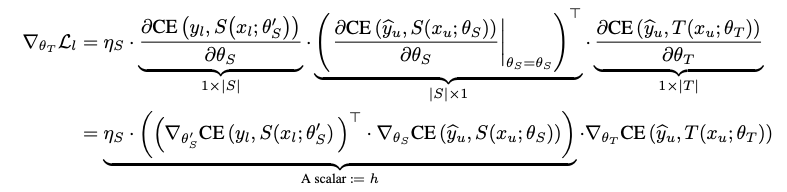
- Meta Pseudo Labels 최적화 방안
- Pseudo Label(PL)을

와 같이 정의!
- \( T \) : 선생님 모델
- \( S \) : 학생 모델
- \( \theta_{T} \) : 궁극적인 목적은 \( \theta_{S}^{PL} \) 이 Labeled Data에서 낮은 Loss를 달성하는 것
즉,

- Student 모델 ( \( \theta_{S}^{PL} \) )의 Loss 기댓값을 낮게 만들어야 함
- \( \theta_{S}^{PL} \) 은 항상 \( \theta_{T} \) 의존적일 수밖에 없음 ( 다른 말로 \( \theta_{T} \) 의 Function이다!)
- 최종 목적 함수 정의

가 Meta Pseudo Label 방법의 최종적인 (이중) 목적함수
- Meta Pseudo Labels 최적화 어려움
- Teacher와 Student의 서로 간의 종속성 때문에, \( \bigtriangledown_{\theta_{T}}\theta_{S}^{PL}( \theta_{T} ) \) 를 계산하기 어려움
- 예를 들어, \( argmin_{\theta_{S}} \)가 모두 구해져 있어야 함
- Meta Pseudo Labels 최적화 해결방안
- Approximate Multi-step \( argmin_{\theta_{S}} \) 을 사용

- 방정식 (3)을 최적화 :
1. \( \theta_{S} \) 를 고정 매개변수로 취급
2. \( \theta_{T} \) 에 대한 고차 종속성을 무시합니다.
- Meta Pseudo Labels 최적화 세부내용
- hard pseudo labels을 사용 ( ∵ large-scale experiments에서, 더 작은 계산량 )
( * hard pseudo labels 란? : [0.25, 0.75] sortmax → [0, 1]로 변환 )
- 작은 실험에서, soft pseudo label과 hard pseudo label 간의 테스트 성능 차이 없었음
- 단, hard pseudo label 사용 시, “modified version of REINFORCE“을 사용
※ “modified version of REINFORCE“
※ “modified version of REINFORCE“
- Student 파라미터 업데이트 → teacher’s objective에서 재사용됨
- 즉, Student와 teacher 간의 교차 최적화 과정(alternating optimization procedure)이 이루어짐

※ 세부 학습 과정
※ 세부 학습 과정

- Meta Pseudo Labels 최적화 - Teacher’s auxiliary losses
- 보조(auxiliary)적인 loss와 함께 사용하면 더 성능이 좋아짐
: Unsupervised Data Augmentation(UDA)
※ UDA Loss 란
※ UDA Loss 란

- 원본 데이터 ↔ 변환 데이터 간의 차이를 학습하는 Unsupervised Learning 방법
- https://visionhong.tistory.com/28 를 추천합니다
- Teacher의 훈련 : Supervised learning objective and a Semi-supervised learning objective를 같이 사용
- Student는 Unlabeled data만 학습
1. Meta Pseudo Labels로 학습하여 수렴
2. labeled data를 fine-tune → ACC 성능을 개선
Meta Pseudo Labels 실험 결과 (Small Scale)
작은 데이터로 먼저 경험적(Empirical) 실험을 진행
- TwoMoon Expreiment
- Semi-supervised Learning 논문에서 종종 보이는 성능확인 방법입니다
- 데이터 : 2000개의 샘플(각각 1000개씩, 2 Class)
Labeled sample은 그중 6개 / 나머지는 Unlabeled 가정
- 비교 : Supervised vs Pseudo Labels(Semi-Supervised 기본) vs Meta Pseudo Labels

- 실험 결과 및 설명 :
1. supervised learning : 레이블 된 인스턴스를 올바르게 학습
But, TwoMoon의 분리된 Cluster 가정(Unlabeled Data)을 활용할 수 없었음
2. Pseudo labels : Unlabeled Data 활용
But, 잘못된 pseudo label을 사용하게 됨 ( ∵ 잘 못 학습된 분류기를 사용) → 데이터의 절반을 잘못 분류하는 분류기가 만들어짐
3. Meta Pseudo labels : 학생 모델의 손실 피드백을 사용하여 교사를 조정하여 더 나은 의사 레이블을 생성
→ 가장 적합한 분류기(Classifier)를 찾음
- 즉, Meta Pseudo Labels는 이 실험에서 Pseudo Labels에서의 확증 편향 문제를 해결
- Semi-supervised 비교 실험
- Semi-supervised Learning 방법론 간의 성능을 확인
- 데이터 : CIFAR-10-4K, SVHN-1K, and ImageNet-10% Experiments
- "Meta Pseudo Labels" 학습 방법 :
1. 동시에 teacher와 student 둘 다 학습
2. Meta Pseudo Labels 학습 완료 후, labeled dataset으로 the student를 finetune
○ SGD - 고정 Learning Rate ( \( 10^{-5} \) )
○ Batch Size : 512
- "Meta Pseudo Labels" 성능 다른 방법보다 좋음. 심지어, 전제 CIFAR 데이터를 학습했을 때 보다 좋음
※ 실험 결과
※ 실험 결과

- 방법론 비교 실험(RESNET-50 아키텍처 고정)
- Meta Pseudo Labels의 효과를 볼 수 있음 ( without distillation )
○ 비교 방법론 : Data Augmentation이나 Regularization
- 데이터 : CIFAR-10-4K, SVHN-1K, and ImageNet-10% Experiments
- "Meta Pseudo Labels" 학습 방법 :
1. Resnet-50을 ImageNet 레이블 데이터로 우선 학습
2. 각 1000 class 별로, 확률이 가장 높은 12,800개의 이미지를 선택 → 1280만 이미지가 선별됨
3. student와 teacher 둘 다를, 4,096 for labeled images and the batch size of 32,768 for unlabeled로 학습
○ teacher는 labeled images으로 학습 후, student의 피드백으로 한 번 더 학습
○ student는 unlabeled로 학습 후, labeled images로 평가
4. 최종 student을 ImageNet Labeled 데이터로, fine-tunning
○ 10,000 SGD steps ( \( 10^{-4} \) )
○ 512 TPUv2 cores로 이틀 학습
※ 실험 결과
※ 실험 결과
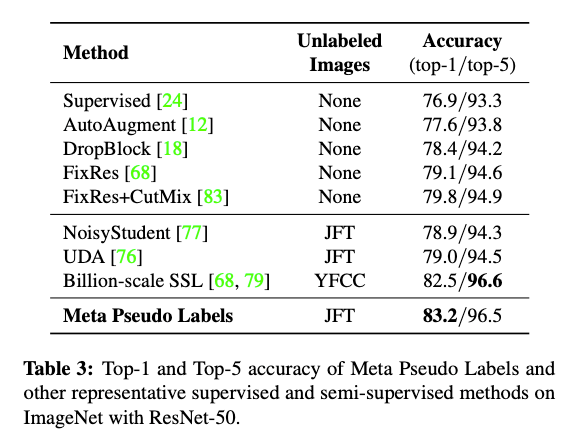
Meta Pseudo Labels 실험 결과 (Large Scale)
ImageNet에서 SOTA를 이루기 위한 실험
- SOTA
- 모델 : EfficientNet-L2 사용 ( ∵ Noisy student에서도 사용 )
○ 추가 실험 모델 : EfficientNet-B6-Wide ( ∵ 좀 더 작은 모델을 테스트 )
○ 좀 더 적은 비용으로 학습하는 Meta Pseudo Labels의 라이트 버전도 설계
→ "Reduced Meta Pseudo Labels"라는 두 개의 네트워크를 동시에 메모리에 유지할 필요를 없앰
- 해상도 : 475 → 512 ( ∵ 모델 병렬 학습(model parallelism implementation) )
※ 병렬화 방법 :
※ 병렬화 방법 :
- 병렬화 필요성 :
- 병렬화 방안 :
- hybrid model-data parallelism framework 사용
1. 2,048 TPUv3 cores를 128개로 나눔 → 16개 core를 한 묶음으로 사용
2. 데이터 병렬화 및 그레디언트 동기화
3. 각 이미지 512*512를 16patch(512*32)로 나누어 각각 16개 core로 분산 처리
○ 475가 아닌 512 해상도로 선택한 이유
4. 각 Weight tensor도 16 파트로 나누어서 각각의 core에 할당
▶ 2,048개 레이블 데이터와 16,384개의 레이블이 지정되지 않은 이미지의 배치 크기를 학습할 수 있게 함
- 데이터 : Labeled Data - ImageNet / Unlabeled 데이터 - JFT dataset has 300 million
○ JFT dataset has 300 million → 130 million 필터링
○ 1. confidence thresholds로 일차로 걸러냄
○ 2. 각 클래스 별로 130k 보다 부족한 클래스는 이미지를 random으로 복제(duplicate)
※ 실험 결과 :
※ 실험 결과 :

Related Works
관련된 접근법들과 Meta Pseudo Labels과의 차이를 비교
- Pseudo Labels
- Self-Training이나, Semi-Supervised Learning(SSL)라고도 불림
- 확증편향(confirmation Bias) 발생할 수 있음
- Semi-Supervised Learning(SSL)
- Supervised Loss(labeled data)와 Unsupervised Loss(unlabeled data)를 결함
- Supervised Loss 대표 접근법 : Cross-entropy
- Unsupervised Loss 대표 접근법
○ Self-supervised loss
○ Self-supervised loss
- Jigsaw Puzzle : 이미지를 Patch로 나눈 후 → 퍼즐의 순서를 맞추듯, 이미지를 학습

- Contrasitive Loss : 1. 이미지를 Patch로 나눈 후 → Patch의 벡터를 유사하도록 학습
2. 다른 이미지의 벡터와는 멀도록 학습

- Self-supervised Loss는 https://hoya012.github.io/blog/Self-Supervised-Learning-Overview/ 블로그
참고하는 것을 추천합니다
○ Label propagation loss
○ Label propagation loss
- 원본 이미지와 원본 이미지를 변화시킨 복제본을 비교하여 함께 학습
- 위에 설명한, Unsupervised Data Augmentation(UDA)도 이 접근법이라고 할 수 있습니다

- label propagation loss는 https://sanghyu.tistory.com/177 블로그를 추천합니다
- Label Smoothing 및 Temperature Scaling
- Label Smoothing : 최적화(Optimization)와 일반화(Generalization) 성능을 높일 수 있는 방법
- 차이점 : Label Smoothing은 soft label로 변화를 고정값으로 처리하지만,
Meta Pseudo Label은 soft label을 Student’s performance에 따라서 적응적(Adaptive)으로 반영
Conclusion
- Semi-supervised learning을 위한 Meta Pseudo Labels 방법을 제안
- Meta Pseudo Labels의 핵심 :
학생의 학습에 도움이 되는 방식으로 Pseudo Label을 생성하기 위해, 교사는 학생의 피드백을 반영
▶ 가장 이상적인 Knowledge Distillation 방향성이 아닐까 생각합니다
- 학습 방법 : 1. 학습 프로세스는 교사가 생성한 유사 레이블 데이터를 기반으로 학생을 업데이트
2. 학생의 성과를 기반으로 교사를 업데이트
- 기존의 많은 Semi-Supervised Learning 방법보다 우수함
- ImageNet에서 90.2%의 상위 1 정확도를 달성하여 이전의 최신 기술보다 1.6% 향상
마치며
- 생각보다 더 빠르게 Transformer 구조가 Vision Task에 침투했습니다.
- 엄청난 데이터 엄청난 모델 크기가 필요한 Transformer를 직접 사전학습을 진행하기에는 많은 한계가 있을 것이고
이러한 Meta Pseudo Label 방식은 새로운 탈출구를 보여주었습니다
- 하지만, Meta Pseudo Label도 단점은 있습니다
1. Teacher 모델과 Student 모델을 동시에 학습시켜야 하므로, GPU Memory가 상당히 필요합니다
2. 대안으로 제시된 Model parallelism. 은 쉽지 않은 학습 방법입니다
3. 480M 모델 사이즈는 여전히 작지 않습니다 ( * 물론 작은 모델에서도 좋은 성능을 보여주어서 가능성은 열려 있습니다)
- 위에 단점에도 불구하고, Meta Pseudo Label가 충분히 중요하고 훌륭한 논문이라는 점은 의심이 없습니다
'딥러닝을 위한 > SOTA(State-of-the-Art)' 카테고리의 다른 글
| [논문요약] Vision분야에서 드디어 Transformer가 등장 - ViT : Vision Transformer(2020) (9) | 2021.07.05 |
|---|---|
| [논문요약] 효율적인 Architecture - EfficientNet(2019) (1) | 2021.04.14 |
| [딥러닝 논문 리뷰] BiT(Big Transfer) - 2019 (0) | 2021.01.22 |