Multi-task learning(MTL)은 다양한 추천 시스템에 성공적으로 활용되고 있습니다.
추천 MTL 중 핵심 논문 중 하나 인 Progressive Layered Extraction(PLE)에 대해서 소개드리고자 합니다.
종합 : ⭐⭐⭐⭐
1. 논문 중요도 : 4 점
2. 실용성 : 4 점
설명 : 추천 Multi-Task Learning 분야에서 핵심 논문
- MMoE를 효과적으로 개선
- 공유 전문가와 작업별 전문가를 명확히 분리
- Task간의 안좋은 영향인 Negative transfer와 시소 현상 완화
- 효율적인 Shared Representation 학습 구현

Multi-Task Learning의 기초가 되는 기술 MoE(Mixture of Experts)의 역사에서 PLE가 핵심 논문으로 소개 되었습니다
추천 분야의 MTL 개요는 다음 내용을 참고하시면 좋습니다
Mixture-of-Experts 추천 시스템 개요 - ②
https://kmhana.tistory.com/53 Mixture-of-Experts 기반 추천 시스템 - ①Mixture-of-Experts (MoE)는 1991년 Jacobs 등이 처음 제한한 고전적인 앙상블 기법입니다.MoE는 모델 용량을 크게 확장할 수 있으며, 계산 오버
kmhana.tistory.com
Abstract
Task 간의 복잡하고 경쟁적인 상호작용으로 인하여, 기존 MTL 모델에서는 성능 저하(negative transfer)를 자주 겪었습니다. 또한, 하나의 작업 성능이 개선되면 다른 작업의 성능이 저하되는 시소(seesaw) 현상이 종종 나타났습니다. 이러한 문제를 해결하기 위해, Progressive Layered Extraction (PLE) 모델을 새롭게 제안했습니다.
PLE는
1. 공유 컴포넌트(shared components)와 작업별 컴포넌트(task-specific components)를 명확히 분리
2. 점진적 라우팅 기법(progressive routing)을 통해 더 깊은 의미 표현(semantic knowledge)을 점진적으로 추출·분리
→ 공동 표현 학습(joint representation learning)과 정보 라우팅(information routing)의 효율을 높입니다.
이 모델은 작업 간의 상관관계 복잡도와 상관없이 여러 작업까지 다양하게 적용할 수 있으며, Tencent의 10억 개 샘플 규모 실데이터에서 우수한 성능(view-count +2.23%, 시청 시간 +1.84% 향상)을 보였으며, MTL 분야에서 SOTA를 달성했습니다.
마지막으로, 여러 공개된 데이터셋 및 다양한 시나리오에서도, 시소 현상을 해소하고 뛰어난 성능을 보였습니다.
Introduction
추천 시스템(이하 RS)에서는 여러 User Feedback을 함께 고려하여, User interest를 모델링하고, 사용자 참여도(engagement)와 만족도를 극대화해야 합니다. 사용자의 만족도는 high dimensionality 문제로 인하여 다루기 어렵지만, 클릭이나 공유, 좋아요, 댓글 등 학습할 수 있는 주요 요소들이 많습니다. 따라서, 최근에는 Multi-Task Learning(MTL)을 추천 시스템에 도입하여, 사용자의 만족도와 참여도 여러 측면을 동시에 모델링하고자 합니다. 실제로 MTL 접근 방식이 주류로 자리 잡았습니다.
MTL은 여러 작업을 하나의 모델에서 동시에 학습하는 방식으로, 작업 간 정보 공유를 통해 학습 효율을 높일 수 있음이 입증되어 있습니다. 하지만 실제 추천 시스템의 여러 작업들은 상호 연관성이 느슨(loose)하거나 심지어 상충(conflicted)하여, negative transfer(성능 저하 현상)가 발생하기 쉽습니다.
또한 기존 MTL 모델들은 한 작업을 개선하면 다른 작업이 희생되는 시소(seesaw) 현상이 발생하여, 단일 모델과 비교해 뚜렷한 이점을 얻지 못하는 경우가 많습니다.
- Cross-stitch Network : 정적(고정) 선형 결합 방식으로 여러 작업의 표현을 합성하여 샘플별 차이를 제대로 반영하기 어렵움
- MMOE : 게이트(gating) 구조를 통해 하위 전문가(expert)를 입력 기반으로 결합하지만, 전문가 간 차별화와 상호작용을 제대로 고려하지 못해 시소 현상이 발생
저자는 복잡한 상관관계를 다루고 시소 현상을 제거하기 위하여, Progressive Layered Extraction (PLE)을 제안했습니다.
- MMOE와 달리, 공유 전문가와 작업별 전문가를 명확히 분리하여, 공유 지식과 작업별 지식 간 유해한 간섭을 줄임
- 여러 층(multi-level experts)과 게이팅 네트워크를 도입
- 하위 층 전문가로부터 깊은 표현(deeper knowledge)을 추출
- 상위 층에서는 작업별 파라미터를 점진적으로 분리하는 구조(Progressive Separation Routing)를 제안
PLE는 실제 산업용 추천 데이터셋(대규모)과 다양한 공개 데이터셋에서, 정상와 복잡한 상관관계 모두에서 기존 최신 MTL 모델들보다 더 우수한 성능을 보였습니다.
- 시소 현상 완화
- 정보 라우팅(information routing)을 통해, 공유 학습(shared learning) 구조를 새롭게 설계
RELATED WORK
2.1 Multi-Task Learning Models
Hard parameter sharing(그림-a)는 가장 기본적이고 보편적으로 사용되는 MTL 구조입니다.
그러나 모든 작업이 같은 파라미터를 직접 공유하기 때문에, 작업 간 충돌(task conflict)이 있을 경우 negative transfer로 이어질 수 있습니다.


이러한 충돌 문제에 대응하기 위해, cross-stitch network(그림-f)와 sluice network(그림-g)은 서로 다른 작업의 표현을 선택적으로 결합하기 위해 선형 결합 가중치를 학습했습니다. 그러나 이들 모델은 모든 샘플에 동일한 정적 가중치를 사용하기 때문에, 실제로는 시소(seesaw) 현상을 해결하지 못합니다. 즉, Gate를 사용하여 다이나믹하게 가중치를 부여하지 못 했습니다.
PLE(Progressive Layered Extraction) 모델은, 게이트(gate) 구조를 활용한 점진적 라우팅(progressive routing) 메커니즘을 사용하여 입력에 따른 동적인 지식을 결합을 수행합니다. 즉, 샘플별로 달라지는 적응적 결합(adaptive combination)을 달성합니다.
다른 Gate 구조와 어텐션(Attention)을 활용한 정보 융합 연구는
- MOE는 하위 수준(Input)에서 일부 전문가(expert)를 공유하고, 게이팅 네트워크를 통해 이들을 결합하는 방식을 처음 제안했습니다.
- ※ 초기 MOE 구조
※ 초기 MOE 구조
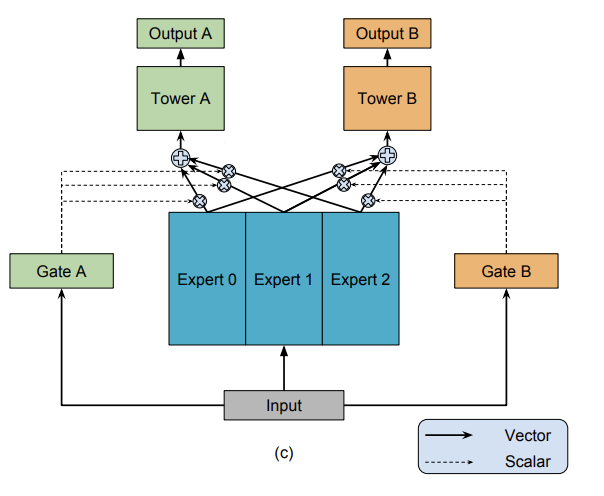
- MMOE는 MOE를 확장해, 작업별로 다른 게이트를 두어 서로 다른 가중치로 전문가를 결합함으로써 MTL 문제를 풀었습니다.
- MRAN은 멀티-헤드(self-attention)를 사용해 서로 다른 피처 집합에서 다양한 표현 하위 공간을 학습하는 기법을 제시했습니다.
하지만 MOE, MMOE, MRAN 모두 전문가와 어텐션 모듈이 모든 작업 간에 공유되며, 작업별 전문가(task-specific)라는 개념이 없습니다.
반면, 우리가 제안하는 CGC(Customized Gate Control)와 PLE 모델은
- 공유 파라미터와 작업별로 고유한 파라미터를 명확히 분리합니다.
- 이렇게 함으로써, 복잡한 작업 상관관계로 인해 발생하는 파라미터 충돌을 방지합니다.
이론적으로 MMOE가 충분히 학습되면 PLE 처럼 수렴할 수 있지만, 사전에 구조적 가이드를 부여하지 않으면 실제 학습 과정에서는 매우 어렵습니다. PLE는 공동 학습(framework of joint learning)과 라우팅(연결) 과정을 통합적으로(inseparable joint) 최적화하며 점진적으로 분리하는 방식을 제안했습니다.
2.2 Multi-Task Learning in Recommender Systems
다양한 사용자 행동을 포착하기 위해 다중 작업 학습(MTL)이 추천 시스템에서 폭넓게 적용되어 왔으며, 실제로 큰 성능 향상을 가져온 사례가 많습니다. 기존의 협업 필터링(collaborative filtering)이나 행렬 분해(matrix factorization)와 MTL을 결합했습니다.
예를 들어,
- 추천 및 설명(Explanation) 작업에서 학습된 잠재 표현(latent representation)에 정규화(regularization)를 추가해, 두 작업을 동시에 최적화
- 협업 필터링과 MTL을 결합해 사용자-아이템(user-item) 유사도를 더 효율적으로 학습
다만 이런 행렬 분해 기반 모델들은, 표현력이 낮고 작업 간 공통점을 충분히 활용하기 어려운 한계가 있습니다.
Hard parameter sharing 구조는 MTL의 가장 기본적인 형태로, 여러 딥러닝 기반 추천 시스템에도 적용되었습니다.
- ESSM은 CTR(Click-Through Rate)과 CTCVR(Conversion Rate)라는 두 보조 작업을 두고, 임베딩 파라미터를 공유함으로써 CVR 예측 성능을 높임
- 순위(ranking)와 평점(rating) 작업을 동시에 학습하는 MTL 프레임워크를 제안
- 문서(text) 추천에 대한 연구에서는 네트워크 하단부의 표현을 공유함으로써 추천 품질을 높임
그러나 Hard parameter sharing은 작업 간 상관관계가 느슨하거나 복잡할 경우, negative transfer나 시소(seesaw) 현상 문제를 겪기 쉽습니다.
Hard parameter sharing 외에도, 더욱 shared learning 매터니즘을 갖춘 MTL 모델을 도입한 추천 시스템들이 있습니다.
- Chen 는 계층적 멀티포인터 코어텐션(hierarchical multi-pointer co-attention)을 활용해,
- 추천 작업과 설명(explanation) 작업 간의 상관관계를 깊이 있게 학습함으로써 성능을 높임
- 다만, 각 작업의 타워(tower) 네트워크가 동일한 표현을 공유 → 작업 충돌(task conflict) 발생 가능성 존재
- YouTube 비디오 추천 시스템에서는 MMOE를 적용
- 여러 게이트를 통해 공유 전문가(expert)를 결합함
- 작업별 차이를 고려하고 여러 목표를 효율적으로 최적화
- 그러나 MMOE는 모든 전문가를 동일하게 취급하여, 명시적인 구분(differentiation)을 두지 않는다는 점에서 한계
3. 추천 MTL에서 시소(SEESAW) 현상
시소(seesaw) 현상이란
Negative transfer는 여러 MTL 연구에서 공통적인 어려움이며, 특히 작업 간 상관관계가 느슨(loose)할 때 더 자주 나타납니다. 또한, 작업 간 상관관계가 복잡하거나, 샘플별로 상관관계가 달라지는 경우(sample dependent), 공유 학습(shared learning)의 효율을 높여도 단일 작업 모델(single-task model)을 상회하기 어렵습니다.
3.1 비디오 추천을 위한 MTL Ranking System
Tencent News에 적용된 MTL Ranking System은 다양한 사용자 피드백(예: 클릭, 공유, 댓글 등)을 바탕으로 뉴스와 동영상을 추천합니다. 그림 2에 나타난 것처럼, 여러 작업(objective)을 이 MTL Ranking System을 통해 다양한 사용자 행동(클릭·공유·댓글 등)을 예측합니다.
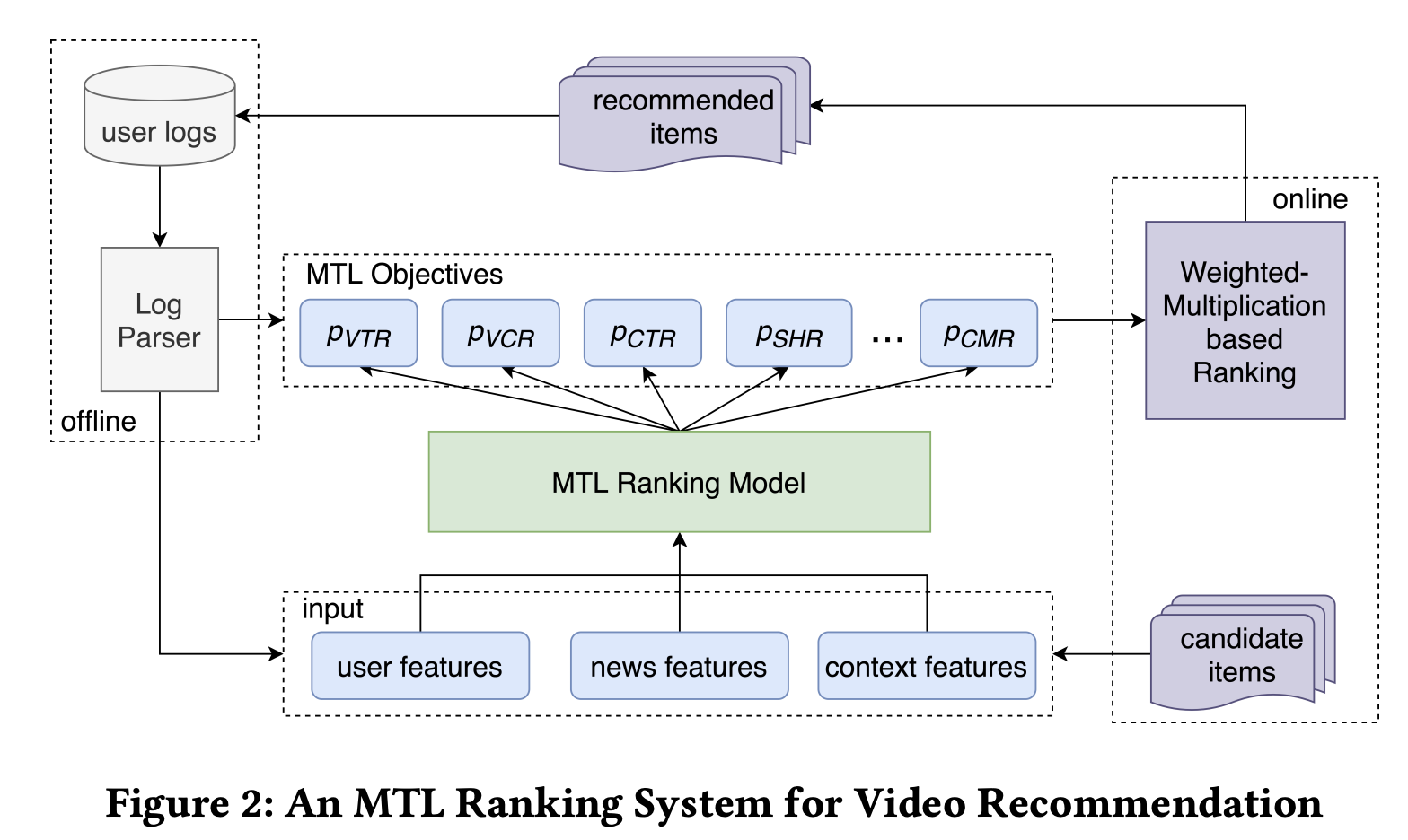
오프라인 학습 단계 : 사용자 로그에 기록된 행동 데이터를 활용해 MTL 모델을 학습
온라인 단계 :
1) 각 요청(Request)마다 MTL 랭킹 모델이 각 작업에 대한 예측 점수를 계산
2) 가중치 곱(weighted-multiplication)을 활용하여 작업별 예측 점수를 하나의 최종 스코어로 합산
$$ \text{score} = p_{\text{VTR}}^{\,w^{\text{VTR}}} \times p_{\text{VCR}}^{\,w^{\text{VCR}}} \times p_{\text{SHR}}^{\,w^{\text{SHR}}} \times \cdots \times p_{\text{CMR}}^{\,w^{\text{CMR}}} \times f(\text{video_len}).
$$
- video_len : 영상 길이에 대한 sigmoid나 log 함수 등 비선형 변환 적용
- 각 Weight는 hyper-parameter로 온라인 실험을 통하여 최적화 튜닝
3) 사용자에게 가장 높은 점수를 받은 동영상을 추천
- VCR 예측은 회귀(regression) : 각 동영상 시청(view)의 완료 비율을 예측하며 MSE 손실로 학습
- VTR 예측은 이진 분류(binary classification) : 시청 시간이 일정 임계값을 넘는 “유효할” 확률을 Cross-Entorypy로 학습
- VTR와 VCR은 서로가 영향을 주는 지표
- 유저 별로 분포의 차이가 큼 : WiFi환경은 시청 확률이 상대적으로 높으나, 자동 재생이 어려운 환경은 시청 확률이 낮음
이처럼 복잡하고 샘플 의존적인 상관관계 때문에, VCR과 VTR을 함께 모델링할 때 시소(seesaw) 현상이 나타납니다.

※ 0.1% 단위의 AUC 혹은 MSE 개선이 실제 시스템에서 큰 효과를 냄
기존의 방법 대부분 시소(seesaw) 현상을 겪었습니다.
- 하드 파라미터 공유와 크로스-스티치는 VTR 성능이 크게 떨어져, negative transfer의 영향을 강하게 받음
- Asymmetric Sharing (그림 1-b)
- 작업 간 비대칭적 상호작용을 반영하기 위해 하위층을 작업별로 달리 공유
- concatenation, summation, averaging 등을 활용해 출력 결합
- Customized Sharing (그림 1-c)
- 공유 파라미터와 작업별 파라미터를 명확히 분리
- 공유 계층으로 추출한 정보를 작업별 계층과 합쳐 타워층 입력으로 사용
- Asymmetric Sharing (그림 1-b)
- MMOE는 두 작업 모두에서 단일 모델보다는 개선됐으나 VCR 개선 폭이 +0.0001 정도로 미미했음
- Gate를 통해 작업 간 차이를 어느 정도 다루지만 한계가 있음
PLE 모델에서만 단일 모델 대비 유의미한 성능향상을 보였습니다.
- 공유 전문가와 작업별 전문가를 구분해 유해한 파라미터 간섭을 억제
- 다중 계층(multi-level)의 전문가와 게이트를 활용해 추상적인 표현을 효과적으로 융합
- 전문자 간 상호작용을 고려해, Progressive Separation Routing으로 복잡한 상관관계에도 효율적인 정보 전이(Knowledge Transfer)
4. Progressive Layered Extraction(PLE)
하위에는 작업별 전문가와 공유 전문가로 구성하며, 상위에는 작업별 타워 네트워크로 모델 구조를 구성했습니다.
- 각 Experts의 sub-networks의 수와 상위 Tower의 multi-layer 수(width, depth)는 hyper-para.
4.1. Customized Gate Control (CGC) 기반의 초기 분리

- 공유 전문가(shared experts) \(m_{s} \) 와 작업별 전문가(task-specific experts) \(m_{k} \)를 명시적으로 분리
- CGC에서는 공유 전문가와 작업별 전문가가 Gating Network를 통해 선택적으로 결합(fusion)
- Gating Network : a single-layer feedforward network with SoftMax
- \( g^{k}(x) = \mathrm{Softmax}(W^{k}_{g} x) S^{k}(x) \)
- \( \mathrm{Softmax}(W^{k}_{g} x) \) : Task \( k \) 별로 계산된 softmax layer (\( \mathbf{W}_g^k \in \mathbb{R}^{(m_k + m_s) \times d} \) )
- shared experts \( m_{s} \) 수와 task별 experts \( m_{k} \) 수
- \( d \) : input representation 차원
- 즉, 공유 및 해당하는 Task 전문가의 input representation에 대해서 softmax 처리 → 공유 및 Task 전문가 score가 나옴
- \( S^k(x) = \left[ E_{(k,1)}^T, E_{(k,2)}^T, \cdots, E_{(k,m_k)}^T, E_{(s,1)}^T, E_{(s,2)}^T, \cdots, E_{(s,m_s)}^T \right]^T \)
- 각 공유 및 Task 전문가는 여러개의 Sub-network(MLP, \(E_{(k,m_k)}^T \) )로 구성되어 있음
- 일반적으로 1–2개 완전연결층 (FC) + 활성화 함수로 구성
- 출력 차원은 입력차원과 동일하게 \( d \)을 가짐
- 이를 통해 다른 작업 고유 지식 간의 간섭(interference)을 줄이면서, 입력에 따라서 동적으로 표현을 융합하는 gating network의 장점을 취함
4.2.1. Progressive Layered Extraction (PLE)

- 더 깊은 semantic 표현을 학습하기 위해서는 더 깊은 구조가 필요 (중간 Layer에 대한 연구는 명확하지 않음)
- CGC의 단일 레이어를 여러 층으로 확장
- Extraction Network : 공유 및 Task 전문가를 분리하지 않고, Gate Network를 사용하여 계층에 있는 모든 전문가 지식을 결함
- 초기 Layer에서는 CGC 처럼 완전히 분리되지 않고, 상위 계층에서 점진적으로 분리됨
- 상위 Layer에서는 raw input을 사용하지 않고, 이전 계층의 Extraction Network 결과를 입력으로 사용
- PLE의 계산 방식은 CGC와 동일 : \( g^{k,j}(x) = w^{k,j}(g^{k,j-1}(x)) S^{k,j}(x) \)
- 차이점은 Shared Experts의 Output이 모든 Experts (task-specific & shared)로 구성됨
4.2.2. Progressive Separation Routing
- 하위층의 모든 전문가 출력을 상위층의 공유 전문가가 흡수하여 더 높은 수준의 공통 지식을 형성
- 이후 각 task-specific 전문가에게 점진적으로 분배되어, 테스크별 깊이 있는 표현이 단계적으로 확립
- “화학적 추출”처럼 점진적으로 추출/집합되어 점진적으로 분리되는 과정과 유사
4.3. Joint Loss Optimization for MTL
구조를 end-to-end로 학습 할 수 있는 Loss Optimization에 대해 제안합니다.
- 일반적인 Weigted sum Loss \( L(\theta_1, \ldots, \theta_K, \theta_s) = \sum_{k=1}^{K} \omega_k L_k(\theta_k, \theta_s) \)으로는 MTL 모델을 추천 시스템에서 공동을 최적하기 여러습니다.
- 특히, 추천 시스템에서는 두 가지 어려움이 있습니다
- 유저의 행동은 sequential하여, 유효한 Sample Space 관리가 필요
- Task 별 Loss weight에 민감함
1. Sample space란?
- 각 작업(task)이 학습에 사용할 유효 샘플 집합
- 클릭(CTR) 작업 → 모든 노출(impression) 레코드
- 시청 완료(VCR) → 실제 재생이 발생한 레코드만
- 공유(SHR) → 공유 버튼을 누른 적 있는 레코드만
2. Union of sample space
- 모든 작업의 샘플 집합을 합집합하여 하나의 큰 배치/데이터셋으로 만듭니다.
- 이렇게 하면 단일 파이프라인으로 데이터를 읽고 전처리할 수 있어 편리합니다.
- 단점: 어떤 작업에는 “의미가 없는” 샘플이 포함될 수 있음.
3. Loss 계산 시 무시(ignore)

- 각 작업 손실을 계산할 때, 자신과 무관한 샘플은 마스킹(masking) 하여 손실에서 제외합니다.
- 예) CTR 손실을 계산할 때 재생이 없어서 노출조차 안 된 레코드는 \( \delta_{\mathrm{CTR}}^i = 0 \) → 손실 미반영
- \( \delta_k^i = \begin{cases} 1 & \text{샘플 } i \text{가 작업 } k \text{에 해당} \\ 0 & \text{아닐 때} \end{cases} \)
$$ L_k(\theta_k, \theta_s) = \frac{1}{\sum_i \delta_k^i} \sum_i \delta_k^i \, \text{loss}_k(\hat{y}_k^i(\theta_k, \theta_s), y_k^i $$
4. Task 별 Loss weight를 동적으로 고려
각 작업별 손실 가중치는 작업간의 상대적 중요성을 결정하기 때문에, 학습 과정에서 민감합니다. 특정 시점에 일부 작업이 지나치게 영향이 커지거나 반대로 거의 학습되지 않는 현상이 발생될 수 있습니다.
- 처음에는 Task별로 initial loss weight( \( \omega_{k,0} \) )를 설정
- updating ratio ( \( \gamma_k^t \) )에 따라서, 각 epoch 마다 Loss Weight를 업데이트
5. 실험 (Experiments)
데이터 셋 : 텐센트 동영상 추천 시스템 - 사용자 수 4천 만명 이상, 26억개의 동영상과 10억건의 샘플
지표 : VCR, CTR, VTR, SHR (Share Rate)
모델 : ReLU, 3 layer MLP (hidden layer size : [256, 128, 64])

Single Task 모델 보다 우수한 성능을 보여줍니다.
또한, 상충되는 Task에 대한 평가를 통하여 시소 현상을 해결했는지 확인했으며, PLE 모델이 기존의 MMOE 대비하여, 상충되는 Task인 CTR과 VCR을 모두 우수하게 개선했음을 보여줍니다.

MTL에서 AUC 또는 MSE를 조금만 개선해도 온라인 지표가 크게 향상 될 수 있음도 확인 할 수 있었습니다.
또한, PLE가 작업간의 협력을 촉진하고 부정적인 전이 및 시소 현상을 방지하는 이점을 입증했습니다.
5.3 Expert Utilization Analysis

각 작업별 전문가와 공유 전문가를 얼마나 활용하고 있는지 확인 해볼 수 있습니다.
PLE는 작업 특성에 따라서, 가중치를 훨씬 더 적응적으로 활용하고 있으며, MMOE가 PLE 구조로 수렴하기 어려운 이유를 보여줍니다.
6. 결론(Conclusion)
- Progressive Layered Extraction (PLE) 모델 제안
- 공유 전문가와 작업별 전문가를 명확히 분리
- 점진적 라우팅으로 negative transfer와 시소 현상 완화
- 효율적인 정보 공유·공동 표현 학습 달성
- 여러 공개 벤치마크에서 기존 SOTA MTL 모델 대비 일관된 성능 향상 확인
- 향후 과제: 작업 그룹 간 계층적 상관관계를 더 깊이 탐구해 모델을 확장 예정
https://github.com/shenweichen/DeepCTR/blob/master/deepctr/models/multitask/ple.py
DeepCTR/deepctr/models/multitask/ple.py at master · shenweichen/DeepCTR
Easy-to-use,Modular and Extendible package of deep-learning based CTR models . - shenweichen/DeepCTR
github.com
'발전중인 AI > 추천(Recommendation)' 카테고리의 다른 글
| Facebook의 추천 MTL - AdaTT(Adaptive Task-to-Task Fusion Network) (3) | 2025.06.16 |
|---|---|
| Mixture-of-Experts 추천 시스템 개요 - ② (0) | 2025.04.06 |
| Mixture-of-Experts 추천 시스템 개요 - ① (1) | 2025.03.14 |
| [논문요약] GDCN(Gated Deep Cross Net, 2023) - 추천 AI의 핵심 트렌드 (0) | 2025.02.03 |
| [논문요약] DNN for YouTube(2016) - 추천 딥러닝 모델의 바이블 (0) | 2022.02.15 |