*크롬으로 보시는 걸 추천드립니다*
https://arxiv.org/pdf/1706.03762.pdf
종합 : ⭐⭐⭐⭐⭐
1. 논문 중요도 : 평가 불가
2. 실용성 : 평가 불가
설명 : 게임 체인저(Game Changer), Transformer 구조의 제안으로 Text 분야를 천하통일!
- Transformer를 제안한 매우 중요한 논문
- Text 분야를 압도적으로 발전시킴
- BERT 등 최신 Text 모델에서 기본적으로 사용하는 구조
- 심지어, 이제는 Image 분야에서도 SOTA를 찍고 있다
( * 개인적인 의견이며, 제 리뷰를 보시는 분들에 도움드리기 위한 참고 정도로 봐주세요)
"언젠간 Transformer를 다루어야지" 미루다가 드디어 정리하게 되었습니다
"Attention Is All You Need"논문이 발표되었을 때의
당시 분위기와 교수님의 말씀이 아직도 생각납니다.
"매우 인상깊은 논문이 발표되었다" 라구요!
그때 저는 텍스트마이닝을 입문 중이었을 때여서, 별 대수롭지 않게 여기었는데,
이 정도로 딥러닝 분야를 뒤집어 놓았다니..
'더 열심히 논문을 읽어볼껄' 조금 후회가 되네요 ㅎㅎ
https://jalammar.github.io/illustrated-transformer/
The Illustrated Transformer
Discussions: Hacker News (65 points, 4 comments), Reddit r/MachineLearning (29 points, 3 comments) Translations: Chinese (Simplified), French, Japanese, Korean, Russian, Spanish, Vietnamese Watch: MIT’s Deep Learning State of the Art lecture referencing
jalammar.github.io
블로그를 주로 참고 했습니다.
고맙게도 그림과 영상으로 Transormer구조를 쉽게(?) 이해를 할 수 있었습니다
총 세 파트로 나누어서 설명할 예정입니다.
1. Transformer 구조
2. Position Encoding
3. 학습 방법 및 결과
총 세 파트로 나누어서 설명할 예정입니다.
첫 번째 파트 "Transformer 구조"에 대해서 소개해 드립니다!
Transformer 의의
○ Transformer 기여
• 기존의 Sequence Transduction(변환) 모델은 인코더(Encoder)와 디코더(Decoder)를 포함하는 구조를 바탕으로,
순환 신경망(Recurrent)나 Convolutional Layer를 사용함
• 좋은 성능을 보인 모델의 특징 : Attention 메커니즘을 활용해서, 인코더와 디코더를 연결한 모델
• Attention 메커니즘만을 사용하는 "Transformer"라는 새로운 구조를 제안
1. 기계번역(Machine Translation) Task에서 매우 좋은 성능
2. 학습 시, 우수한 병렬화(Parallelizable) 및 훨씬 더 적은 시간 소요
3. 구문분석(Constituency Parsing) 분야에서도 우수한 성능 → 일반화(Genelization)도 잘됨
※ 구문분석이란?
※ 구문분석이란?
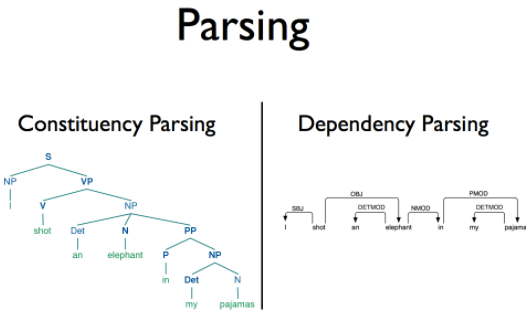
- Constituency Parsing : 명사구나 동구와 같은 구단위의 구조를 파악
- Dependecy Parsing : 단어와 단어 간의 주종관계를 파악
Transformer Introduction
Background
○ Sequential 문제를 풀기 위한, 이전 연구
• LSTM, GRU 등을 활용한, "Recurrent(순환) 구조"가 언어 모델링 및 기계번역 등의 Task에서 확고한 입지를 다져왔음
• Recurrent(순환) 구조는 Input과 Output Sequence를 활용
: \( h_{t} \) : \( t-1 \) 를 Input과 \( h_{t-1} \) 를 통해 생성
→ 이러한 구조로 인해 일괄처리가 제한됨
(∵ 순차적으로 \( t \) 이전의 Output이 다 계산되어야 최종 Output이 생성)
1. 병렬화 제한됨
2. Seqeunce의 길이가 길어질수록 더 취약해짐
→ Factorization Trick이나 Conditional Computation으로 계산 효율성을 증대했으나 한계점 존재
○ Sequential Computation 문제를 풀기 위한, 이전 연구
• CNN 구조를 통해 병렬화 고려 했지만, 여전히 한계점 존재
1. 인코더와 디코더를 연결하기 위한 추가 연산 필요
2. 원거리 Position 간의 Dependencies(종속성)을 학습하기 어려움
※ CNN을 활용한 병렬화 방안
※ CNN을 활용한 병렬화 방안
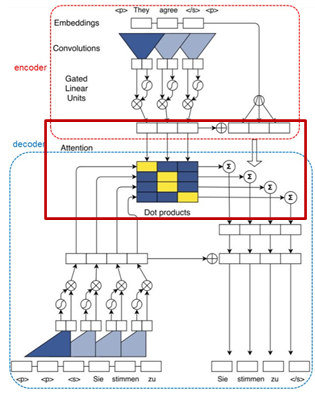
- 빨간 박스 : 인코더와 디코더를 연결하기 위한 추가 연산 필요
○ Attention 메커니즘
• Sequence 모델링에서 필수적인 요소
• Input이나, Ouput Sequence에 관계없이, Dependencies(종속성)을 학습할 수 있음
• 하지만, 일반적으로 RNN에 붙여서 사용했음
※ Attention 구조
※ Attention 구조
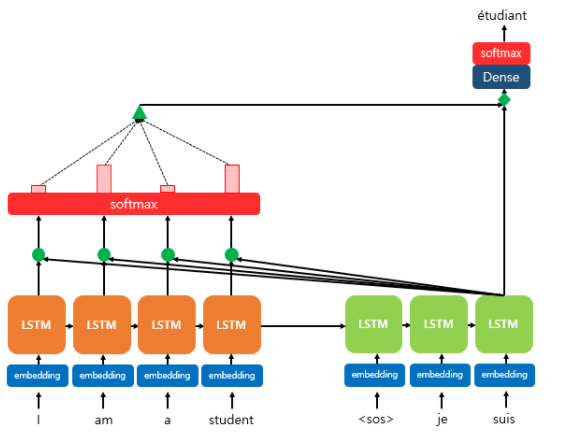
○ Self-Attention 메커니즘
• "Intra-Attention"이라고도 불림
• 단일 Sequence 안에서의 Position들을 연결
• Self-Attention은 독해, 요약, Sentence Representation에서 효과적
• "Recurrent Attention"이 "Sequence-Aligned Recurrent" 보다 End-to-End 학습에서 더 좋은 성능
- Sequence-Aligned Recurrent 참고 자료 : https://dos-tacos.github.io/concept/alignment-in-rnn/
○ Transformer의 특징
• 일괄처리가 되지 않는 Recurrance 구조 피함 → Self-Attention만으로 입˙출력의 Representation을 계산
• Input과 Output 사이의 "Global Dependency"를 학습
• 병렬화(Parallelizable) 우수 ( P100-8 GPU → 12 시간 학습 )
• SOTA 달성
Model Architecture
○ 전체적인 구조
• 기계번역 모델은 일반적으로 "Encoder-Decoder" 구조를 가짐
• 입력 \( (x_{1}, ... , x_{n}) \)은 Encoder를 통해, \( \textbf{z} = ( z_{1}, ... , z_{n} ) \) 로 표현 및 매핑됨
• Encoder로 표현된 \( \textbf{z}\) 를 활용하여, 한 번에 한 Element 씩 Output Sequence \( ( y_{1}, ... , y_{m} ) \)가 생성
- Auto-Regressive : 생성된 Symbol은 다음 생성 과정에서 추가 입력으로 사용

○ Encoder 구조
• \( N = 6 \) 의 동일한 Layer Stack으로 구성
• 각 Layer는 2개의 Sub-Layer로 구성
1) Mulit-Head Self-Attention 메커니즘
2) Position-wise Fully Connected Feed-Forward Network
: 1x1 Conv Layer가 2개 이어진 것과 같음
: Position 별로 동일한 Fully Connected Feed-Forward Network가 적용(Dim = 2048)
• 각 Sub-Layer는 Residual Connection 및 Layer Nomalization 적용
$$ \textup{LayerNorm}(x + \textup{SubLayer}(x)) $$
• Residual Connection 적용을 용이하게 하기 위해, Sub-layer, Embedding, Output Dimension을 512로 통일
( ∵ Residual Connection 적용을 위해선, Input과 연결된 Output의 Dimenstion이 동일해야 함)

○ Decoder 구조
• \( N = 6 \) 의 동일한 Layer Stack으로 구성
• 각 Layer는 3개의 Sub-Layer로 구성
1) Masked Mulit-Head Self-Attention 메커니즘
- Decoder의 Mulit-Head Self-Attention은 Masking을 사용하여,
후속(Subsequent) Position은 Attention 안 하도록 조정
- Position(\( i ) \)를 예측할 때는 , (\( i ) \) 보다 작은 위치에 알려진 Output에만 의존
- Output Embedding은 One Position 씩 Offset(주소 참조)
2) Encoder의 Output에 대해 Mulit-Head Self-Attention 메커니즘 수행
3) Position-wise Fully Connected Feed-Forward Network
○ Encoder-Decoder 구조 정리 및 요약
1. Encoder는 Self-attention layers 구조로 구성
- 이전 Encoder Layer에서의 출력 → 현재 Encoder Layer에서의 동일 Position의 입력
- 각 Encoder Layer는 이전 Layer로부터 모든 위치를 처리한 정보를 활용
2. Decoder Layer 특징
- Sequence-to-Sequence 모델에서의 일반적인 인코더-디코더 Attention 메커니즘을 모방
- Query : 이전 Decoder Layer에서 가지고 옴
- Key 와 Value : encoder에서의 output에서 가지고 옴
- 각 Decoder는 Encoder의 모든 Position정보를 사용함
3. Decoder에서의 모든 Position 정보 사용 방지
- auto-regressive 속성(Property)을 위해 왼쪽으로부터 넘어오는 정보흐름을 방지해야 함
- 잘못된 연결에 해당하는 Softmax 값을 마스킹(-∞)으로 세팅
○ Attention에 대한 고찰
• 크게 두 가지 종류가 있음
※ Attention 종류 :
※ Attention 종류 :
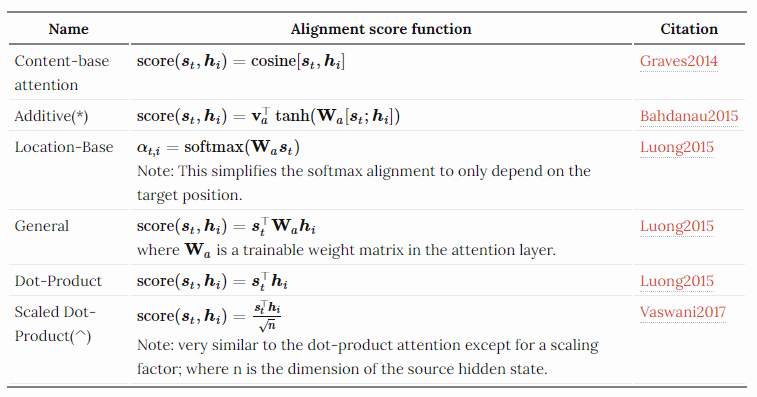
1) Additive Attention : Single Hidden Layer로 구성된 Feed-Forward Network를 활용 → Compatibility(일치성) 계산
※ Additive Attention 란
※ Additive Attention 란
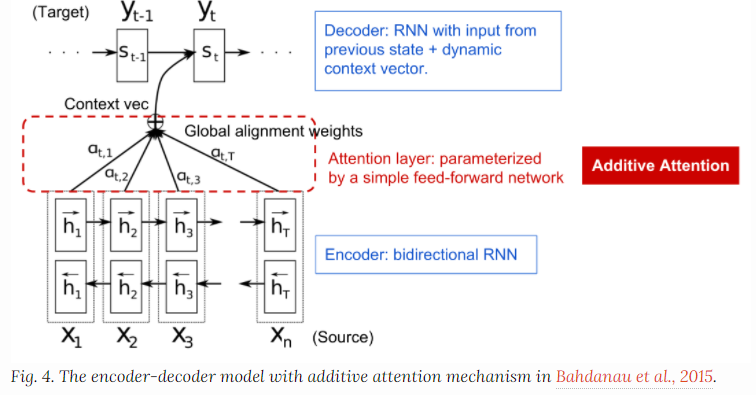

2) Dot-product(Multiplicative) Attention :
- 장점 : 효율적인 행렬곱 구성으로, 실제로 더 빠르고 공간 효율적
- 단점 : 작은 Key 벡터의 차원(\( d_{k} \)) 에서는 두 메커니즘이 유사한 성능을 보이지만,
더 큰 \( d_{k} \) 에서는 Additive Attention이 더 좋음
○ Attention 핵심 계산 과정

: Self-Attention을 계산하기 위해서 총 "6 단계"를 거침
1) 입력 벡터(여기서는 Word Embedding)를 활용하여, 3개(Query, Key, Value)의 백터를 생성
- 학습과정에서 각각의 3개의 행렬을 곱하여 생성( Word Embedding 차원 : 512)
- 3개(Query, Key, Value)의 백터 차원 : 64 ( * 더 작을 필요 X )

2) Score 계산
- Ex : "Thinking"이란 단어의 Self-Attention을 계산한다고 가정
- "Thinking"에 대한 각 입력 문장 내에서의 단어별 "점수화" 필요
* 점수화란 : 특정 위치에서 단어(Query)가, 다른 위치의 단어들을 얼마나 Attention 할 것인지 결정하는 점수
- Query와 Key 백터를 내적 하여 계산

3) Key 백터 크기의 제곱근만큼을 Scaling
- Ex : \( d_{k} = 64 \) → \( \frac{1}{\sqrt{ d_{k}}} = \frac{1}{8} \)
- 더 안정적인 Gradient를 얻기 위해서, Scaling 진행
* 기존 Dot-product Attention에서는,
\( d_{k} \) 의 증가 → Softmax 함수를 매우 작은 Gradient로 만들어 버림
기존의 단점을 해결하기 위해, \( \frac{1}{\sqrt{ d_{k}}} \) 만큼 Scaling

4) Softmax 계산을 통해, 전체 Score를 정규화
- 전체 합이 1인 양수의 값으로 변환
- 위치에 따른, 단어별 다른 주의(Attention)를 기울이도록 함

5) Value 백터에 Softmax값을 곱함
- 가중치 합을 준비하는 단계
- 주의를 기울이고자 하는 단어의 값은 유지하고, 관련 없는 단어는 거의 제외
6) Value 백터를 가중치 합 계산
- 해당 Position에서의 단어의 Self-Attention Output 출력
- Query와 Key의 Compatibility(일치성) Function에 의해 계산됨


※ Query, Key, Value 백터에 대한 고찰
- Query : Attention 계산에서 기준이 되는 벡터
- Key : Query 벡터와 Compatibility(일치성)이 높은 단어를 찾기 위한 벡터
- Value : 다른 단어와의 Attention이 반영 최종 Representation를 얻기 위한 벡터
* 개인적인 의견으로 참고 정도 해주세요
○ The Beast with Many Head
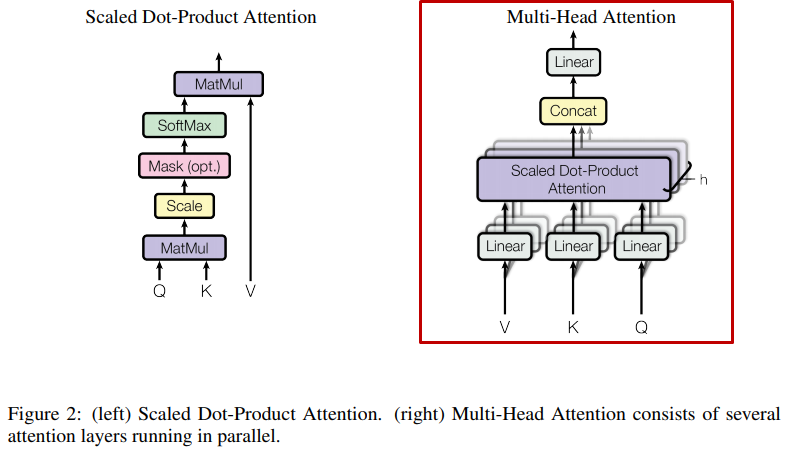
• Multi-Head 개념을 추가하여, Attention Layer의 성능을 향상
• 단일 Attention 보다, h 개의 Attention 구조가 더 성능이 뛰어남을 확인
• Query, Key, Value를 서로 다른 선형 Projection 하는 것이 유리
• Attention을 병렬 수행하여, \( d_{v}-dimensional \) Output 값을 생성
1) 다른 위치에 있는 단어를 집중(Attention)하는 능력 향상
- 예를 들어, 'It'이 가리키는 단어를 알고 싶을 때 유용
2) 여러 "Representation Sub-space"를 제공
- 8개의 Scaled Dot-Product Attention을 사용하여, 여러 표현의 Attention을 학습 가능토록 함
- ①서로 다른 위치에 있는 ②서로 다른 Represntation Sub-space의 정보를 ③결합하여, Attention 할 수 있음
• 단일 Attention은 Averaging 효과로 다양한 Attention 탐지가 억제됨
• Head의 축소된 차원( \( d_{v} \times Head = 64 \times 8 = 512 \))으로 인해, 총 계산 비용은 Single-Head Attention( \( d_{model} = 512 \) )과 유사


○ 최종 Self-Attention 계산 과정 요약

○ Position-wise Feed-Forward Networks
• Encoder 및 Decoder 모두 Position-wise Feed-Forward Networks로 구성됨
• Position-wise Feed-Forward Networks는 각 Position 별로(Separatley) 적용 및 동일(Identically)하게 적용
• Linear Transformation → ReLU → Linear Transformation

• Layer 별로는 다른 Parameter를 가짐
• \( d_{model} = 512\) , \( d_{inner-layer} = 2048 \)
○ Embedding 및 Softmax 구성

• 각 Token은 Embedding 벡터로 변환( Input, Output Embedding 및 역 Embedding 포함하여 3번)
- Embedding은 동일 Matrix를 사용
• 디코더에서의 번역 결과는, Linear Transformation → Softmax → Token화 과정을 거침
※ Embedding 구조
※ Embedding 구조

Transformer의 핵심 구조에 대해서 다루었습니다.
다음 파트에서는
1. Transformer 구조
2. Position Encoding
3. 학습 방법 및 결과
를 다룰 예정입니다!
저에게 있어서, Transformer 논문은 매우 중요하지만, 읽는 것을 미뤄둔 숙원 같은 논문이었는데
드디어 정리를 할 수 있어서 후련합니다!
중요한 논문이였던 만큼 정리된 많은 자료를 참고할 수 있었고, 그 자료들을 모으는것을 중심으로 정리했습니다
부족한 부분은 말씀해주시면 반영 하겠습니다!
'딥러닝을 위한 > 가이드(Guide)' 카테고리의 다른 글
| [논문요약] Transformer 등장 - Attention Is All You Need(2017) ② (0) | 2021.08.03 |
|---|---|
| [논문요약] Classification 학습방법 - Bag of Tricks(2018) (1) | 2021.04.01 |
| 딥러닝을 위한 논문 가이드 (8) | 2021.02.13 |