*크롬으로 보시는 걸 추천드립니다*
2. Metric Learning을 위한 딥러닝
- Multi-Grain
- CGD(Combination of Multiple Global Descriptors)
arxiv.org/pdf/1903.10663v4.pdf
CGD 논문을 중심으로 소개드리고자 합니다.
Global Descriptor(SPoc, MAC, GeM)를 병렬로 연결하는 CGD 모델의 특성상,
kmhana.tistory.com/18?category=842461
Metric Learning 이란 - Feature 추출
*크롬으로 보시는 걸 추천드립니다* 본 "Metric Learning 이란 - Feature 추출"을 보시기 전에 kmhana.tistory.com/14 Metric Learning(Image Retrieval) 이란? - 기본 *크롬으로 보시는 걸 추천드립니다*..
kmhana.tistory.com
을 먼저 보시는 것을 추천드립니다.
종합 : ⭐⭐⭐⭐⭐
1. 논문 중요도 : 5점
2. 실용성 : 5점
설명 : 좋은 아이디어! 뛰어난 성능! 쉬운 구현! 3박자를 모두 갖춘 Metric Learning의 핵심 논문
- 여러 Global Descriptors들을 앙상블 했더니, Image Retrival 성능이 좋았다.
- 모델을 효과적이면서 End-to-End로 학습하면서, 앙상블(Ensemble)의 효과를 구현한 논문!!
- Classification Loss + Triplet Loss + Multipl Global Descriptors의 삼중연
- 구현도 쉬운데, 성능도 뛰어나다면, 쓰지 않을 이유가 없다.
( * 개인적인 의견이며, 제 리뷰를 보시는 분들에 도움드리기 위한 참고 정도로 봐주세요)
이 논문이 나오자마자 읽었었고, 꼭 다루고 싶었던 논문을 이제 다룰 수 있어 기쁩니다.
CGD의 중요성으로 인하여, Multi-Grain논문 보다 먼저 다루게 되었습니다.
그만큼 중요한 논문이라고 생각합니다.
앞으로 Metric Learning의 대표 논문 중 하나가 될 거라 의심치 않습니다.
실용성을 높게 생각하는 저로써는, Metric Learning 분야에서 이 보다 더 좋은 논문은 많지 않아 보입니다.
( * 게다가 한국인이 쓰셔서 그런지 더 잘 읽히는 느낌!)
Abstract
기본 아이디어 :
1. Image Retrieval 분야에서 여러 "모델의 앙상블(Ensemble)"이나,
"Global Descriptor의 결합"을 통해 좋은 성능을 내었음
* Global Descriptor : SPoC, MAC, GeM 등을 의미함
2. But, 개별 모델을 따로 학습한 후 앙상블 하는 것은, 어렵고 Time과 Memory의 비효율적이다
▶ 앙상블 효과를 위해, Multiple Global Descriptor를 사용하며, End-to-End 학습을 진행하고자 함
CGD 의의:
1. 유연성 및 확장성 : CNN backbone, Global Descriptor, Loss, Dataset에 대해서, 자유롭게 사용 가능
+ End-to-End 학습
2. 결합된 Multiple Global Descriptor 성능확인: Single Descriptor 보다 더 뛰어난 성능을 보임
3. 여러 Image Retrieval 분야에서 SOTA를 기록
Related Work
1) Global Descriptor
: CNN기반에 Global Descriptor가 SIFT 같은 Hand-Craft기반 보다 더 좋은 성능을 보임
- SPoC (Sum pooling - GAP라고 봐도 됨)
- MAC (Max pooling - Globa Max Pooling라고 봐도 됨)
- GeM (Genalized-mean Pooling - SPoC와 MAC의 사이)
kmhana.tistory.com/18?category=842461 참고
2) Attention 기반 :
- 본 논문에서는 인용하지 않았지만, "DELF" or "DELG"가 하나의 예
- 단점 : 1) Network의 크기와 학습시간이 늘어날 수 있다
2) 학습을 위한, 추가 Parameter가 필요함
※ Attention 기반 예시
※ Attention 기반 예시
www.dlology.com/blog/easy-landmark-image-recognition-with-tensorflow-hub-delf-module/
Easy Landmark Image Retrieval with TensorFlow Hub DELF Module | DLology
Posted by: Chengwei 2 years, 8 months ago (Comments) Have you ever wonder how Google image search works behind the scene? I will show you how to build a mini version of a landmark image recognition pipeline that leverages TensorFlow Hub's DELF(DEep Lo
www.dlology.com
3) 앙상블 기반 :
- 여러 모델을 통해 성능을 Boost 할 수 있는, 기술
- 여러 Attention Module을 통해, 단일 Embedding을 학습하는 Attention-based 앙상블도 제안됨
- 단점 : 1) 모델의 복잡성이 증가함에 따라, 계산량이 증가됨
2) 학습자(learners) 간의 다양성을 위한 Control 필요
▶ CGD는 End-to-End 학습일 뿐만 아니라, 앙상블 효과를 위한 Diversity Control이 필요 없다
CGD의 Framework
1) BackBone :

- ResNet, ShuffleNet-v2, BN-Inception 등을 사용
- Input Size : 224x224 ← Image Retrieval Task대비 낮은 해상도로 학습
- 핵심 설정 : Stage 3과 Stage 4 사이의 Down-Sampling을 제거하여, 마지막 Feature Map 크기를 증가
2) Main Module : Multiple Global Descriptors

○ Global Descriptor의 수식 :
$$ f = \left [ f_{1}...f_{k}...f_{C} \right ]^{T}, \hspace{1cm} f^{(g)}_{k} = \left ( \frac{1}{\left | \chi_{k} \right |}\sum_{x\in \chi_{k} }x^{p_{k}} \right )^{\frac{1}{p_{k}}} $$
- \( p_{k} = 1 \) : SPoC ("S" 로 표기)
- \( p_{k} = \infty \) : MAC ("M" 로 표기)
- \( p_{k} = 3 \) : GeM ("G" 로 표기 - \( p_{k} \) 는 학습하거나, 여러 수를 사용할 수 있으나, 3으로 고정 함)
○ Mulitple Global Descriptor 처리과정 :
1. Global Descriptor를 활용한 Feature 추출
2. FC Layer를 활용한 차원축소(Dimemsionality Reduction)
3. \( l_{2}-normalization \) 을 활용한, Nomalization 진행
4. 3단계까지 진행한 Feature를 Concat
5. Ranking Loss를 활용하여 학습
- 여러 Ranking Loss를 사용할 수 있으나, Batch-hard Triplet을 사용
○ Mulitple Global Descriptor 장점 :
1. 적은 추가 Parameter만으로, 앙상블 효과 제공
2. 학습가능 하기 때문에, End-to-End 가능
- 여러 Ranking Loss를 사용할 수 있으나, Batch-hard Triplet을 대표로 사용
3. 특별한 Loss(각 Global DescriptorBranch마다의 학습을 조절)가 필요하지 않음
3) Auxiliary Module : Classification Loss

○ Auxiliary Module 기능 :
1. 첫 번째 Global Descriptor에 연결되어, CNN Backbone을 미세조정
2. Auxiliary(Cross-entropy) Loss : Inter-class distance를 빠르게 최대화함
- 모델 학습을 빠르고 안정적이게 도와줌
○ Auxiliary Module(Classification loss)의 수식 :
$$ L_{softmax} = - \frac{1}{N}\sum_{N}^{i=1}log\frac{exp\left ( \left ( W^{T}_{y_{i}}f_{i}+ b_{y_{i}}\right )/\tau \right )}{\sum_{M}^{j=1}exp\left ( \left ( W^{T}_{j}f_{i}+ b_{j}\right )/\tau \right )} $$
- \( N \) : Batch-size
- \( M \) : Class 수
- \( y_{i} \) : \( i-th \) Label
- \( f \) : Global Descriptor
- \( \tau \) : Temperature Scaling Parameter (default : 1)
: 1 보다 낮으면, 학습하기 어려운 Example의 Gradient를 크게 만들어 학습에 도움을 줌
: Inter-class는 떨어지게, intra-class는 Compact 하게 학습에 도움을 줌

- Label Smoothing : 과적합을 방지하고, Genalization 향상시킴 + Learn Better Embedding
* Label Smoothing : estimating the marginalized effect of a label-dropout
4) Framework 구성
○ Multiple Global Descriptor 구성 조합 :
- \( p_{k} = 1 \) : SPoC ("S" 로 표기)
- \( p_{k} = \infty \) : MAC ("M" 로 표기)
- \( p_{k} = 3 \) : GeM ("G" 로 표기 - \( p_{k} \) 는 학습하거나, 여러 수를 사용할 수 있으나, 3으로 고정 함)
- 위에 세가지 Global Descriptor를 조합하여, 총 12가지 조합이 가능함
* 예시 1 : GSM 표기 - First global Descriptor인 GeM이, Auxiliary Classifciation loss에 연결됨
: GeM (2048 → 512-dim), SPoC (2048 → 512-dim), MAC (2048 → 512-dim)으로 차원 축소 후 Concat
Concat한 최종 Embeding이 1536-dim으로 유지
* 예시 2 : SM 표기 - First global Descriptor인 SPoC이, Auxiliary Classifciation loss에 연결됨
: SPoC (2048 → 768-dim), MAC (2048 → 768-dim)으로 차원 축소 후 Concat
Concat한 최종 Embeding이 1536-dim으로 유지
○ Multiple Global Descriptor 조합 선택법 :
- 각 Global Descriptor는 다른 특징을 가지고 있음 ( ∴ 데이터셋에 특징에 따라, 선택이 중요함)
※ Global Descriptor 특징 설명
※ Global Descriptor 특징 설명

- SPoC는 광범위한 영역에 대해서 집중
- MAC는 극소적인 영역에 대해서 집중
- GeM는 SPoC와 MAC의 중간정도의 영역에 대해서 집중
- 결합할 Global Descriptor 수는 Output 차원에 따라서 결정되어야 함
: 작은 Output 차원 → 작은 수의 Global Descriptor 추천됨
1. Single Global Descriptor로 성능을 평가함
2. 1등, 2등 Global Descriptor를 결합함
※ 1등, 2등 Global Descriptor 중 어떤 Global Descriptor를 Classification loss에 연결할지는 해봐야함
CGD 실험 및 결과
○ 실험 기본 조건 :
- GPU : Tesla P40 - 24GB memory
- Backbone : ResNet-50, BN-Inception, ShuffleNet-v2, SE-ResNet-50
- Input Size : 224x224 ( 학습 시, 252x252에서 Random Crop)
- Embedding Dim : 1536-dim
- Augmentation : Horizontal Filp
- Optimizer : Adam (1e-4)
- Margin : 0.1 - triplet loss
- \( \tau \) : 0.5
- Batch Size : 128
○ Ranking Loss와 Softmax 결합실험 :

- Table 1 : Ranking + classification loss > 단독 Ranking Loss
- Table 2 : Label Smoothing + Temperature Scaling 성능 가장 좋음
○ Architecture 실험 :

- Figure 2 : A 구조 - 개별 Ranking loss / B 구조 - Concat → FC → Raking / CGD 구조 - FC → Concat → Ranking
º B 구조와 같이 Concat 후, FC Layer를 쌓으면, 각 Global Descriptor의 특성이 섞여버린다.
- Table 3 : CGD의 성능이 가장 좋음
- Table 4 : Feature 통합 시, Concat > Sum
○ Multiple Global Descriptor 조합 실험 :

- 12 가지 Muliple Global Descriptor 실험을 진행함
- Multiple Global Descriptor > Single Global Descriptor
- 1등과 2등의 Glabal Descriptor의 조합이 성능이 가장 좋았음
- 데이터의 특징에 따라서, 가장 좋은 Muliple Global Descriptor 조합이 다름
○ Multiple Global Descriptor 시각화 :

- 초록 박스 : 정답 / 빨간 박스 : 오답
- SPoC(S)는 광범위한 범위를 MAC(M)는 극소적인 범위에 집중함
- SM( SPoC + MAC)는 위에 두 Descriptor의 특징을 결합함
- 여러 Global Descriptor를 결합할 경우에, 이미지의 유사성을 계산하는데 도움이 됨
○ CGD Framework의 유연성 :
1) Ranking Loss
- CGD의 장점으로 저자는 유연성을 꼽고 있으며, 다양한 Ranking Loss를 사용할 수 있음
- Hard, Sami-Hard Triplet, HAP2S loss, Weighted Sampling Margin loss 등을 사용할 수 있음

- 일반적인 Hard Triplet Loss의 성능이 좋은 편임
- HAP2S P의 성능이 가장 좋음
º 실용적인 측면에서는 Triplet을 사용하는 것이 좋아보임
º Margin Loss : paperswithcode.com/paper/sampling-matters-in-deep-embedding-learning
º HAP2S : paperswithcode.com/paper/hard-aware-point-to-set-deep-metric-for
2) Backbone
- 여러 Backbone(BN-Inception, ResNet)을 사용할 수 있음
- 동일 Backbone(BN-Inception, ResNet)을 사용하는 다른 방법론 보다, CGD를 사용했을 때 더 높은 성능보임
- Compact한 모델(ShuffleNet-v2)에서도 좋은 성능
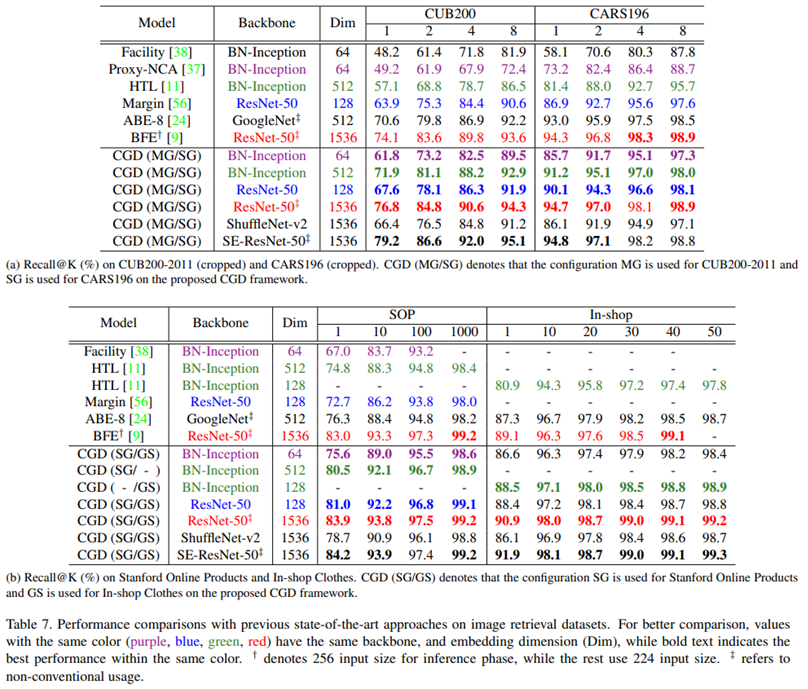
- 성능이 좋은 Backbone(SE-ResNet-50)을 CGD와 사용했을 때, 가장 좋은 성능을 보여줌
※ Backbone 실험 결과
※ Backbone 실험 결과
마치며
- Metric Learning을 해보고 싶다면, CGD를 가장 먼저 시도해봐야 한다고 생각한다.
- 몇 가지의 논문과 비교해봤었는데, 논문 구현이 쉬웠으며 게다가 성능도 뛰어났었다.
- Metric Learning 분야에서, 몇 가지 논문을 더 다룰 수 있지만,
이 논문보다 더 좋은(실용적이면서, 성능이 뛰어난) 논문을 찾지 못했다.
- 여유가 된다면, Batch Sampling이나 Loss Fuction(Margin이나 HAP2S)를 다룰 예정이지만, 상대적 중요도는 낮다
※ 중요하지 않다는 것은 절대 아닙니다. 오히려 "CGD의 효과가 엄청나게 크다"고 할 수 있습니다
'실용적인 AI > Metric Learning' 카테고리의 다른 글
| [번외] Metric Learning을 위한 딥러닝 - CBAM(Conv Block Attention Module) (0) | 2021.03.03 |
|---|---|
| Metric Learning 이란 - Feature 추출 (0) | 2021.02.12 |
| Metric Learning 이란 - 학습 방법(Loss) (0) | 2021.02.05 |
| [번외 - 논문요약] Deep Face Recognition : A Survey - ① (0) | 2021.02.02 |
| Metric Learning(Image Retrieval) 이란? - 기본 (5) | 2021.02.02 |