*크롬으로 보시는 걸 추천드립니다*
본 "Metric Learning 이란 - Feature 추출"을 보시기 전에
Metric Learning(Image Retrieval) 이란? - 기본
*크롬으로 보시는 걸 추천드립니다* Active Learning(능동적 학습)에 이어서, 다룰 주제는 Metric Learning입니다! Active Learning(능동적 학습) 설명 : kmhana.tistory.com/2?category=838050 실용적인 Deep Lea..
kmhana.tistory.com
를 먼저 보시면서, Metric Learning의 기본을 잡고 가시는 걸 추천드립니다.
이번에는
1.2) Feature를 어떻게 처리할 것인가?
1. 어떻게 뽑을 것인가? (GeM, SPoc, MAC)
2. 뽑은 Feature를 어떻게 후-처리할 것인가?(Whitening)
에 대해서 설명드리고자 합니다.
○ Classification VS Retrieval :
MultiGrain: a unified image embedding for classes and instances [arxiv.org/pdf/1902.05509.pdf]
이란 논문에서 Image Classifcation Task와 Image Retrieval을 비교 설명해주고 있습니다.
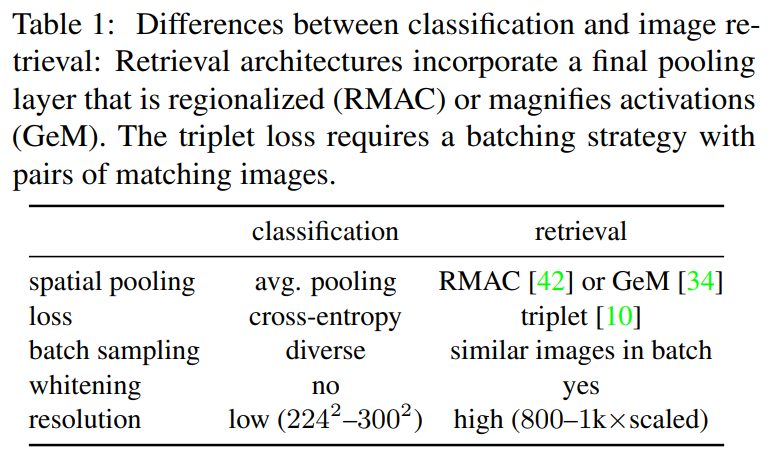
- Loss : kmhana.tistory.com/17?category=842461에서 설명한 것처럼
이미지 검색(Retrieval) Task는 유사도를 학습할 수 있는 Triplet Loss를 기초로 학습합니다.
- Batch-Sampling: 이미지 검색(Retrieval) Task는, 유사도를 학습할 수 있도록
Anchor, Positive, Negative가 하나의 쌍으로 구성해서, 학습합니다.
- Resolution(해상도) : 이미지 검색(Retrieval) Task는, 더 높은 해상도의 이미지를 사용합니다.
Image Retrieval은 더 어려운 Task이며, 더 고화질 데이터를 사용하므로, 이에 따른 추가 고려가 필요합니다.
* Multi-Grain 논문에서 이에 대한 내용을 다룰 예정입니다.
1. 어떻게 뽑을 것인가? (GeM, SPoc, MAC)
- Spatial Pooling : 이미지 검색(Retrieval) Task는 Global Averaging Pooling이 아닌,
GeM(Generalized Mean Pooling)을 사용
º GeM (Genalized-mean Pooling) 수식:
$$ f^{(g)}_{k} = \left ( \frac{1}{\left | \chi_{k} \right |}\sum_{x\in \chi_{k} }x^{p_{k}} \right )^{\frac{1}{p_{k}}} $$
- \( \chi_{k} \) : k-번째 Feature
- \( p \) : Localization과 관련된 Hyper Parameter
: \( p = 1 \) 은 SPoC(Sum-Pooled Convolutional = Global average pooling)
: \( p = \infty \) 은 MAC(Maximum Activation of Conv = Global max pooling) [arxiv.org/pdf/1511.05879.pdf]

º 효과 : Global Max pooling과 Averaging pooling 사이의 효과를 가짐 ( 주로, P=3을 사용)
기존의 Feature Descriptor(SPoc, MAC, R-MAC)보다 더 좋은 성능을 보여줌
※ 번외 : R-MAC
※ 번외 : R-MAC
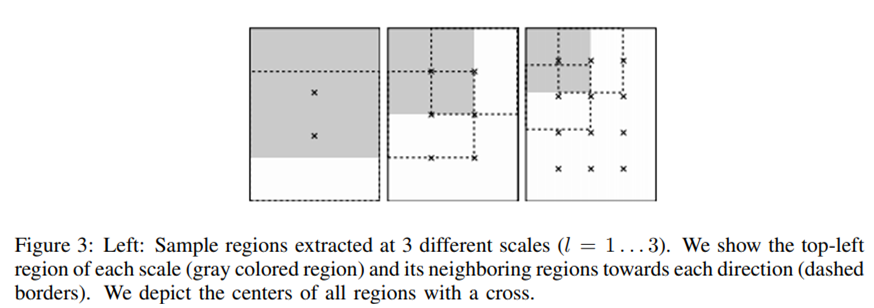
○ R-MAC 목적 : Local 정보가 사라지는 Global Max pooling의 단점을 보완하기 위해서, R-MAC를 제안함
○ R-MAC hyper-paramter ( \( l \) ) : Region의 크기를 정함 - \( l = 1 \) 일 때 최대
○ R-MAC 적용 과정 :
1. Region 별로 Maxpooling을 진행 - Feature map 개수(K) x Region 수만큼 생성
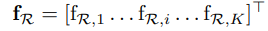
2. 합산 후, L2-Normalization 진행
2. 뽑은 Feature를 어떻게 처리 할것인가?(Whitening)
- Whitening : 이미지 검색(Retrieval) Task는, 추출된 Feature에 PCA Whitening를 진행
º 효과 : Whitening를 거진 Feature의 Euclidean Distance는 Mahalanobis distance와 같음
* Whitening이란 : 입력 벡터를 각각 상관관계가 없고, 각각이 분산 1로 변환 → White Noise Vector로 변환함
( ∵ 이미지의 구조와 특징을 강조하기 위한 방법 = Reduce Redundancy)

※ 번외 : PCA(Principal Component Analysis) vs ZCA(Zero-Phase Component Analysis) Whitening
※ 번외 : PCA vs ZCA Whitening
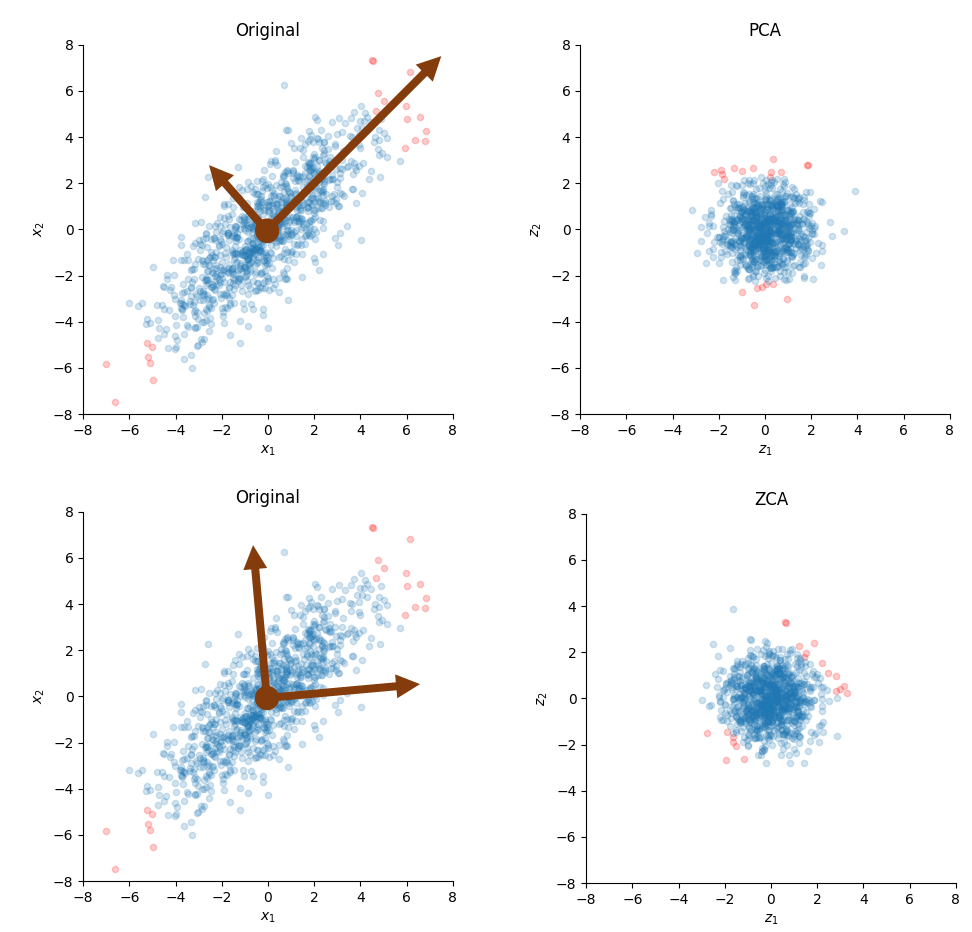
○ Whitening 목적 :
1. 변수간 Correlation을 없애기
2. 분산을 1로 동일하게 만들기
○ PCA Whitening(위 그림) : 데이터 압축이 목적인 경우 최적
- 두 벡터의 Correlation은 없앴으며, 분산을 동일하게 변환, But 빨간 점은 변환된 축에 따라서, Rotation 됨
- 새로 생긴축은 , 분산에 따른 주성분(Principal Component)으로 정렬되기 때문에 데이터 압축이 가능
○ ZCA Whitening(아래 그림) : 변환된 벡터를 입력 벡터와 가능한 유사하게 유지하는 경우
- 두 벡터의 Correlation은 없앴으며, 방향성도 그래도 보존
- 축은 유지되기 때문에, 데이터를 압축하진 못함
- Data Augmentation에서 PCA Whitening보다 더 자주 사용됨( ∵ ZCA는 이미지의 형태가 유지됨)
cbrnr.github.io/posts/whitening-pca-zca/
* PCA와 ZCA에 대한 자세한 설명에 대해서 요청이 오면 추가해 드리겠습니다.
지금까지, Metric Learning을 위해서, 'Feature를 어떻게 처리할 것인가?'라는 주제를 중심으로 설명했습니다.
다음은
2. 딥러닝을 위한 Metric Learning
- Multi-Grain
- CGD(Combination of Multiple Global Descriptors)
논문을 중심으로 소개드리고자 합니다.
'실용적인 AI > Metric Learning' 카테고리의 다른 글
| [번외] Metric Learning을 위한 딥러닝 - CBAM(Conv Block Attention Module) (0) | 2021.03.03 |
|---|---|
| Metric Learning을 위한 딥러닝 - CGD(Combination Global Descriptors) (1) | 2021.02.20 |
| Metric Learning 이란 - 학습 방법(Loss) (0) | 2021.02.05 |
| [번외 - 논문요약] Deep Face Recognition : A Survey - ① (0) | 2021.02.02 |
| Metric Learning(Image Retrieval) 이란? - 기본 (5) | 2021.02.02 |