어떤 문제를 해결하고자 할지에 따라서, 머신러닝의 테스크(Task)가 나누어집니다.
기초 머신러닝 태스크(Task)
기본적인 Task는
○ 회귀(Regression) : 연속형 문제를 해결하며, 예를 들어 "하루에 몇 건의 메일이 오는지"와 같은-∞~+∞ 범위의 문제를 다룹니다
○ 분류(Classification) : 범주형 문제를 해결하며, 예를 들어 "받은 메일이 스팸인지 아닌지"와 같은 범주형 문제를 다룹니다
다시 분류 문제는
○ 이진 분류(Binary Classification) : 두 개의 카테고리를 맞추는 문제를 해결하며, 예를 들어 스팸인지 아닌지를 다룹니다.
○ 다중 분류(Multi Classification) : 세 개의 이상의 카테고리 문제를 해결하며, 예를 들어 받은 메일의 카테고리를 추정합니다.

각각의 Task를 해결하기 위해서, 케라스는 대표적인 Loss 함수를 제공하고 있습니다.

각각의 Loss를 다루는 함수들을 보면, 머신러닝 문제가 각각의 테스크를 어떻게 해결하는지를 알 수 있습니다.
- 회귀(연속형) 문제 : \( MSE = \frac{1}{N}\sum_{i}^{N}\left ( y_{i} - \hat{ y_{i}} \right )\ \) 를 Loss로 사용하여,
-∞~+∞ 범위문제를 추론값과 실제값의 차이의 합을 최소로 만들도록 최적화 시킵니다.

- 분류(카테고리) 문제 : \( BCE = -\frac{1}{N}\sum_{i}^{N} y_{i} \, log \: \hat{y_{i}} + (1-y_{i})\,log\, (1-\hat{y_{i}}) \) 를 Loss로 사용하며, sigmoid와 softmax를 활용합니다.
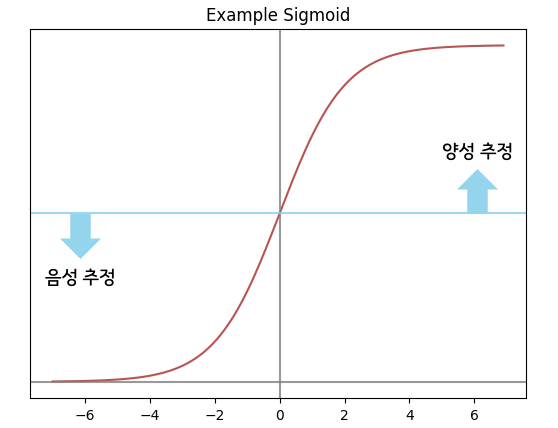
○ 이진 분류(Binary Classification) : Threshold 설정된 값을 넘으면 양성(Positive)으로, 낮으면 음성(Negative)으로 추정합니다.
- 일반적으로, 0.5를 Threshold로 설정하나 음성이나 양성의 중요도에 따라서 변경합니다.
○ 다중 분류(Multi Classification) : Softmax값을 활용하여, k개의 클래스 중 가장 높은 예측값에 해당되는 클래스로 추정합니다.
실전 머신러닝에서의 Task
하지만, 실전에서는 위의 상황처럼 딱 떨어지지 않는 경우가 있습니다.
실전 상황에서 벌어지는 일들을 확인해 보고 어떻게 해결하는지 사례를 통해 설명드리고자 합니다.
1. 다중 레이블링 태스크(Task)
위의 "일반적인 ML 테스트 유형"에서 아직 설명하지 않은 내용이 있었는데요.
다중 레이블(Multi Label) 테스크입니다.
다중 레이블이란, 하나의 샘플에 여러 레이블이 중복으로 붙어 있는 케이스를 의미합니다.
실제 현업에서, 다중 레이블이 생기는 상황은 다음과 같습니다.
○ 실제 중복 카테고리 : 예를 들어, 하나의 뉴스는 정치와 경제 카테고리 모두에 포함될 수 있습니다.
○ 명확하지 않은 기준 : 반도체의 불량을 구별하는 경우, 검수자에 따라 똑같은 제품도 양품으로도 불량으로도 레이블링 할 수 있습니다.
○ 관리자의 변경이나 정책 : 관리자가 바뀌거나 이벤트를 하는 경우 등등, 외부 환경에 따라 같은 상품에 중복 레이블링 될 수 있습니다.
이 밖에 다양한 사유로 다중 레이블 문제가 발생됩니다.
이 처럼 깔끔하지 않은 데이터로 인하여, 성능저하가 일어나거나 모델링 자체가 불가능한 경우가 있습니다
하늘이 무너져도 솟아날 구멍은 있다는 속담처럼
이러한 악조건 속에서도 문제를 해결할 수 있는 몇 가지 방법이 있습니다.
카테고리 추론 방식 변경
1. 모든 Class를 Binary Class로 구성 : 각각의 중복되는 클래스가 있다면, 각각의 카테고리를 하나의 Binary class로 생각합니다 - Class가 너무 많은 경우에는 사용하기 힘들며, 각각의 카테고리 별 Theshold를 설정해야 하는 단점이 있습니다.
- 그럼에도 불구하고, 각각의 카테고리를 (준) 독립적으로 예측할 수 있다는 장점이 있습니다.
2. Top N개의 클래스를 추론 : Softmax를 활용하여, 후보군 선별(Candidate Filtering)처럼 Top-N개의 상위 클래스를 추론합니다.
- 사용자나 현업과의 커뮤니케이션이 필요하며, 실서비스의 제약이 있는 경우도 있습니다.
- Top-N개의 추론결과를 사용 시 비용대비 사용성이 떨어지지 않아야 합니다.
카테고리 재정비
1. 카테고리 별 기준 재정비 : 중복되거나 겹치는 카테고리는 통합합니다. 중복 클래스가 불필요한 경우가 이에 해당합니다.
- 현업과의 커뮤니케이션을 통해, 중복 클래스가 불필요함과 모델을 활용한 자동화의 한계가 있음을 설명해야 합니다.
2. 계층적 클래스(Hierarchical Class)로 재정비 : 중복 클래스가 꼭 필요한 경우, 상위 클래스와 하위클래스로 최대한 묶습니다.
- Hierarchical Softmax로 계층적 구조의 클래스를 해결할 수 있습니다.
3. '기타' 클래스 설정 : 특정 카테고리가 너무 희귀하거나 카테고리 기준이 매우 불명확한 경우,
- '기타' 클래스를 두어 AI모델의 분류가 어려운 데이터와 사람의 추가적인 분류가 필요한 클래스로 명시합니다.
"카테고리 재정비"에 경우, 여러 데이터를 레이블링을 해야 하고 통합하려는 카테고리 간의 유사성 등을 파악해야 합니다.
이것은 많은 시간과 인력 리소스가 들어갑니다.
엄청난 비용의 증가로 인하여, AI 모델을 활용하는 방법들도 많이 연구되고 있습니다.
대표적인 방법으로, Auto-Labeling과 Active Learning이 있습니다.
Active Learning vs Auto Labeling
* 크롬으로 보시는 걸 추천드립니다 * 2. 딥러닝을 위한, Active Learning - Core-set : kmhana.tistory.com/6?category=838050 - Loss for Active Learning : kmhana.tistory.com/10?category=838050 - Discriminative Active Learning(DAL) : kmhana.ti
kmhana.tistory.com
자세한 차이는 해당 페이지에 작성하였습니다.
요약하지면,
○ Auto Labeling(자동 레이블링) : AI 모델이 높은 확신(High Confidence)을 가지는 데이터를 자동으로 레이블링
○ Active Learning(능동적 학습) : AI 모델이 중요한 데이터를 선별(불확실성↑ or 분포고려)하여, 레이블링 요청
입니다.
2. 클래스 간의 불균형 문제
현업에서는 클래스간의 불균형으로 문제는 흔하게 볼 수 있습니다.
클래스간의 불균형을 어떻게 해결했는지에 따라 모델의 성능이 결정되기도 합니다.
실제 현업에서, 클래스간의 불균형이 생기는 상황은 다음과 같습니다.
○ 비용 문제 : 특정 클래스를 수집하는데 엄청난 비용이 드는 경우입니다.
- 질병 데이터를 수집하는 경우 승인 및 규제 준수 등의 조치가 필요하며 큰 비용이 발생합니다.
○ 데이터 접근이 어려운 경우 : 반도체의 불량을 구별하는 경우, 양품보다 불량의 개수가 훨씬 더 많은 경우가 해당됩니다.
클래스 간의 분균형 문제를 해결할 수 있는 몇 가지 방법을 소개하고자 합니다.
샘플링 기법
1. 오버 샘플링(Over Sampling) : "개수가 적은 클래스"의 샘플을 "많은 개수의 클래스"의 샘플 수만큼 복사
- Over Sampling 하는 클래스의 샘플을 오버피팅하게 됩니다.
2. 언더 샘플링(Under Sampling) : "개수가 많은 클래스"의 샘플을 "개수가 적은 클래스"의 샘플 수 만큼 삭제
- Under Sampling 하는 클래스 샘플을 날려, 학습하는 데이터의 전체 볼륨이 줄어듭니다.
3. SMOTE(Synthetic Minority Over-sampling Technique) : "개수가 적은 클래스"의 샘플을 KNN알고리즘을 활용하여 합성
- 3.1 : data point에서 가까운 이웃 k개 선별 / 3.2 : k개의 이웃 간의 임의 값을 곱하여 새로운 데이터로 합성(보간)합니다.
모델링을 통한 해결
1. Class Weight 설정 : 개수가 적은 클래스를 틀리는 경우에 대해서 더 많은 가중치를 부여하여 학습합니다.
- 개수가 적은 클래스의 중요도가 다른 클래스 보다 높아야 합니다.
- 클릭률 예측이나, 불량 예측 등의 문제를 해결하는데 적합합니다.
2. Focal Loss 활용 : Easy 샘플에 대한 가중치를 줄이고, 맞추기 어려운 샘플을 더 잘 맞추기 위한 방법입니다.
- Tensorflow의 기본 함수로 내장됨. 기본 함수로 포함되었단 의미는 많이 활용되었다는 뜻입니다.
3. 평가 지표 활용 : 정확도(Accuracy)가 아닌 Recall, Precision이나 F1-score 등을 평가 지표로 활용합니다.
이상탐지 Task로 확장
1. Anomaly Detection : 소수의 클래스를 이상치(Anomaly)로 정의하고 탐지하는 모델을 만듭니다.
- 소수의 클래스를 제거하고 일반적인 클래스만을 학습하여, 학습한 데이터와의 분포에서 벗어난 샘플을 탐지합니다.
- https://hoya012.github.io/blog/anomaly-detection-overview-1/
Anomaly Detection 개요: [1] 이상치 탐지 분야에 대한 소개 및 주요 문제와 핵심 용어, 산업 현장 적
이상치 탐지 (Anomaly Detection) 분야에 대해 주요 용어들을 정리하며 소개를 드리고 산업 현장에 적용되는 여러 가지 사례들을 소개 드립니다.
hoya012.github.io
다음 파트에서는 머신러닝의 기본요소에 대해서 소개하고자 합니다.
1. 일반화와 과적합(최적화)
2. 데이터 셋 구성
3. 과적합 방지 방법
3.1 데이터 수집과 Augmentation
3.2 정규화
3.3 모델 규모
3.4 학습 하이퍼 파라미터 설정
3.5 Early Stopping
입니다.
해당 파트를 재밌게 이해하기 위한 사이트
https://playground.tensorflow.org/
도 참고하시면 좋습니다!