Transformer 설명 중 두 번째와 세 번째 파트
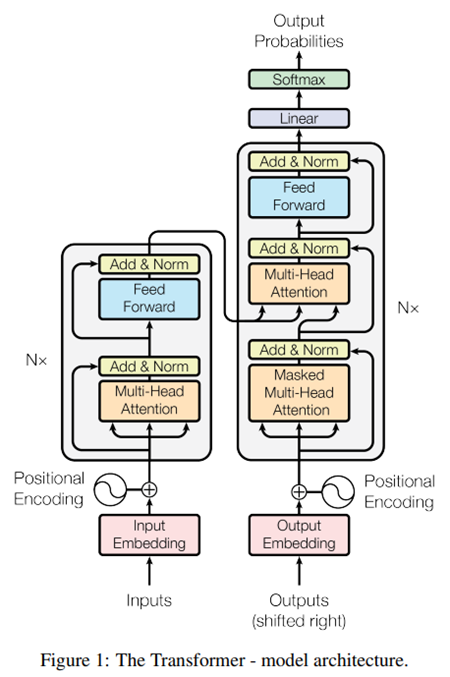
1. Transformer 구조
2. Position Encoding
3. 학습 방법 및 결과
"Position Encoding"와 "학습 방법 및 결과"에 대해서 소개해 드립니다!
Transformer 의 구조에 대한 설명은
Have A Nice AI
kmhana.tistory.com
에서 요약해 두었습니다!
https://jalammar.github.io/illustrated-transformer/
The Illustrated Transformer
Discussions: Hacker News (65 points, 4 comments), Reddit r/MachineLearning (29 points, 3 comments) Translations: Chinese (Simplified), French, Japanese, Korean, Russian, Spanish, Vietnamese Watch: MIT’s Deep Learning State of the Art lecture referencing
jalammar.github.io
위키독스
온라인 책을 제작 공유하는 플랫폼 서비스
wikidocs.net
를 주로 참고 했습니다.
Position Encoding의 필요성
○ Position Encoding의 필요성
• Transformer는 Convolution이나 Recurrence를 사용하지 않음
• Recurrence Layer와 다르게, "Multi-Head Attention Layer"와 "Position-wise Feed-forward Network"는
Sequence와 독립적(Independently)으로 계산됨
• Sequence와 독립적(Independently)인 특징
- 계산을 병렬로 수행할 수 있음
- Sequence 정보를 모델링하는데, 한계가 있을 수 있음
▶ Transformer Model은 위치정보를 입력 Sequence에 넣어서 처리
○ Position Encoding의 특징
• Sequence의 순서 정보를 넣어주기 위해선, 상대 또는 절대 위치 정보를 주입해 주어야 함
→ 이를 위해 Transformer는 "Position Encoding"를 적용
• Position Encoding을 Encoder와 Decoder의 입력 임베딩에 더함(Add)
- Position Encoding의 Dimension : \( d_{model} = 512 \)
- 입력 임베딩과의 합산을 위해서, 동일 Dimension(\( d_{model} = 512 \))을 사용
○ Position Encoding 수식
$$ PE_{pos,2i} = sin(pos/10000^{2i/d_{model}}) $$
$$ PE_{pos,2i+1} = cos(pos/10000^{2i/d_{model}}) $$
$$ PE_{pos} = [cos(pos/1),\space sin(pos/10000^{2/d_{model}})),\space cos(pos/10000^{2/d_{model}})), ... ,sin(pos/10000) ] $$
• Position Encoding 수식 설명
- 홀수 : Cosine / 짝수 : Sine 함수를 활용
- \( i \) : 임베딩 차원의 위치
- \( pos \) : Word의 위치

• Learned Positional Embedding과 비교실험 결과 유사한 성능 확인
※ Learned Positional Embedding과 비교실험 결과

- 성능 차이가 거의 없음을 확인
• Attention을 활용하면 상대적인(Relative) Position을 쉽게 학습할 수 있다는 가정하에, Sinusoid로 구성(절대적 거리)
• Sinusoid로 구성(절대적 거리)의 장점 :
- 학습과정에서 만나지 못한 긴 문장도 대응 가능
- 후속 연구들에서는 상대적(Relative) 거리의 Positional Encoding을 자주 사용
• Positional Encoding의 조건
- 고정 오프셋(Offset) K가 있을 때, 선형 변환을 통해 표현 가능해야 함
- 즉, \( PE_{pos+K} \)는 \( PE_{pos} \)의 선형식으로 표현 가능해야 함
- Sinusoid로 구성(절대적 거리)은 선형식으로 표현 가능
※ 증명

○ Position Encoding의 필요성
• Transformer는 Convolution이나 Recurrence를 사용하지 않음
• Recurrence Layer와 다르게, "Multi-Head Attention Layer"와 "Position-wise Feed-forward Network"는
Sequence와 독립적(Independently)으로 계산됨
• Sequence와 독립적(Independently)인 특징
- 계산을 병렬로 수행할 수 있음
- Sequence 정보를 모델링하는데, 한계가 있을 수 있음
▶ Transformer Model은 위치정보를 입력 Sequence에 넣어서 처리
○ Position Encoding의 형태
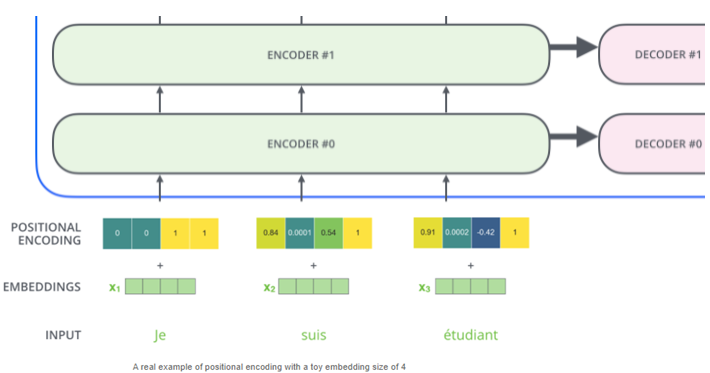
• Input Embedding과 Positional Encoding 값을 더해서, Transformer에 입력
• Input Embedding + Positional Encoding → Q/K/V Vector로 변환 → Dot-Product Attetnion
• 각 단어의 위치나, 단어 사이의 거리를 결정하는데 도움을 줌
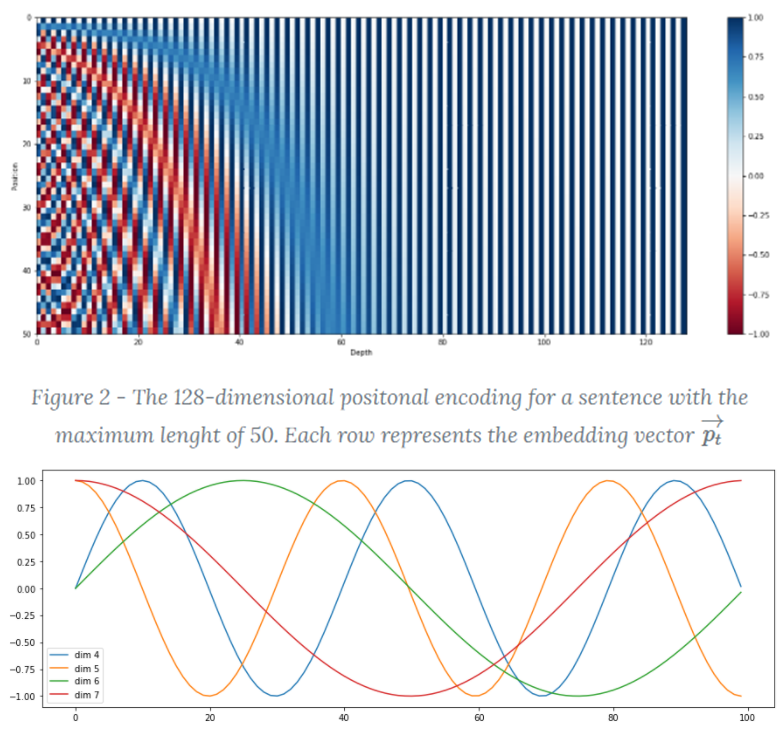
※ Positional Encoding 코드
※ Positional Encoding 코드
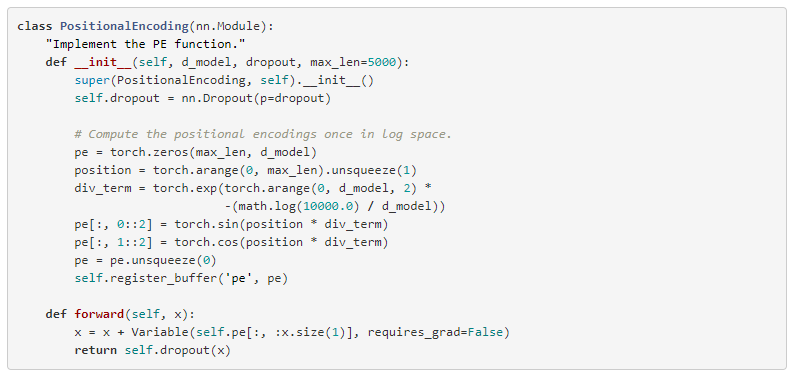
성능 비교 및 실험
○ Self-Attention의 필요성
• Recurrent 및 Convolutional Layer와의 비교
• 세 가지 측면을 고려
1. Layer당 Computational Complexity
2. 병렬 작업(Paralleized Computation)이 필요한 양
- 필요한 순차 적업의 최소 수
- Minimum Number of Sequential Operations required)
3. 네트워크 내에서의 장거리 종속 성간 경로의 최대 길이
- Path Length between long-range Dependencies in Network
- Maximum path length between any two input and output positions in networks
- 장거리 종속성(dependencies)을 학습하는 것은 Sequence Transduction Task에서 핵심적인 과제
- Input 및 Output Sequence에서의 Position 간의 경로가 짧을수록,
더 쉽게 장거리(Long-Range) 종속성을 학습 가능
- 네트워크 내 노드에서 정보를 교환하기 위해서, 통과해야 되는 경로의 길이
- 두 입출력 Position 사이의 최대 경로 길이도 함께 비교
○ Self-Attention의 필요성 결과

• Computational Complexity :
- \( n < d \) 인 경우 Self-attention이 Recurrent 보다 빠름
* 기계 번역 SOTA 모델에서 자주 발생되는 상황(중요!)
* 기계 번역 SOTA 모델에서 자주 발생되는 상황
- Word-Piece나 Byte-Pair Representation을 사용하여 \( n < d \) 인경우가 종종 발생
- Word-Piece 란 :
https://lovit.github.io/nlp/2018/04/02/wpm/
Word Piece Model (a.k.a sentencepiece)
토크나이징 (tokenizing) 은 문장을 토큰으로 나누는 과정입니다. 텍스트 데이터를 학습한 모델의 크기는 단어의 개수에 영향을 받습니다. 특히 Google neural machine translator (GNMT) 와 같은 Recurrent Neural N
lovit.github.io
- Byte-Pair 란 :
위키독스
온라인 책을 제작 공유하는 플랫폼 서비스
wikidocs.net
※ Word-Piece나 Byte-Pair Encoding은 NLP에서 매우 중요한 부분이므로, 꼭 한번 보시길 권해드립니다!
- 매우 긴 Sequence인 경우, Computational Performace 향상을 위해,
Self-Attention은 이웃(Neighborhood) \( r \) 만큼으로 제한할 수 있음
→ 단 Maximum Path Length는 \( O(n/r) \) 증가
• Sequential Operations :
- Recurrent는 Sequnce 작업 시 순차적으로 수행 : \( O(n) \)
- Self-Attention은 동시에 모든 Position이 연결됨 : \( O(1) \)
• Maximum Path Length :
- Self-Attention은 동시에 모든 Position이 연결됨 : \( O(1) \)
- Recurrent는 Sequnce 작업시 순차적으로 수행 : \( O(n) \)
- Covolutional은 Sequnce 작업시 Kernal Size에 영향 받음 : \( O(\log_{k}(n)) \)
* 계산 복잡도 산정 방법
• 해석력(XAI) :

- Self-Attention은 좀 더 해석 가능함
- 문장의 구문 및 의미 구조와의 관련성을 학습하는 것으로 보임
- 각 Attention Head는 다른 Task를 수행
Transformer 학습 방법
○ Training Data 및 Batch
• Training Data 약 450 만 문장 쌍(영어-독일어 세트) - 공유된 약 37000 Token 사용
• Training Data 약 3600만 문장 쌍(영어-프랑스어 세트) - 공유된 약 32000 Token 사용
• Byte Pair Encoding(BPE) 사용
○ Hardware 및 Schedule
• 8개의 P100 GPU 사용
• Base Model 기준
- 1 Step : 0.4 Sec 소요
- 100,000 Step 및 12 시간 학습
• Bid Model 기준
- 1 Step : 1 Sec 소요
- 300,000 Step 및 3.5 일 학습
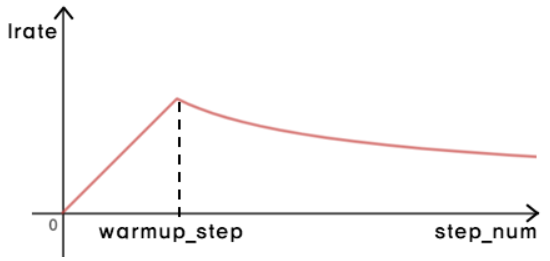
• Learning Rate Schedule
- 1 Step : 1 Sec 소요

- Warm-up Step : 4000 - 선형적으로 증가
- Warm-up Step 이후, 역의 제곱근에 비례하여 Learning Rate를 감소
위키독스
온라인 책을 제작 공유하는 플랫폼 서비스
wikidocs.net
○ Regularization
• Dropout : \( p_{drop}= 0.1 \)
- 각 Sub-Layer Output(Residual Connection 및 Normalization) 전에 Dropout 적용
- Encoder 및 Decoder에 적용
→ "Embedding" 및 "Positional Encoding" 합(Sum) 이후에 Dropout 적용
• Label Smoothing : \( \varepsilon_{ls}= 0.1 \)
- 불확실함을 추가 학습하여, 정확도와 BLEU 점수 향상
Transformer 실험 결과
○ Machine Translation
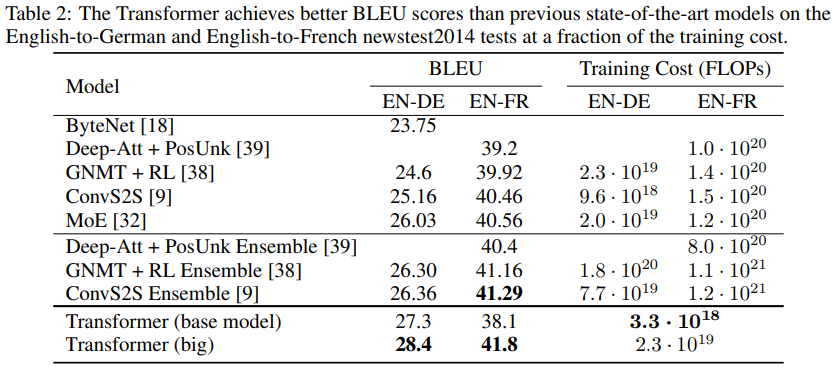
• 상대적으로 적은 Training Cost로 우수한 성능, 심지어 Ensemble 모델보다 우수
- Base Model : 5 Checkpoint의 평균으로 얻어진 Single Model을 사용
- Big Model : 20 Checkpoint의 평균으로 얻어진 Single Model을 사용
• Beam Search 사용 : Beam Size 4, Length Penalty \( \alpha = 0.6 \)
- 학습이 완료 후, Dev Set에서 Beam Search와 관련된 최적의 Hyper-Paramter를 선택
- 번역 시, 최대 출력 길이 : 입력 길이 + 50 ( 가능하면 짧게 번역 )
※ Beam Search 란 - Machine Translation에서 사용되는 기술
※ Beam Search 란
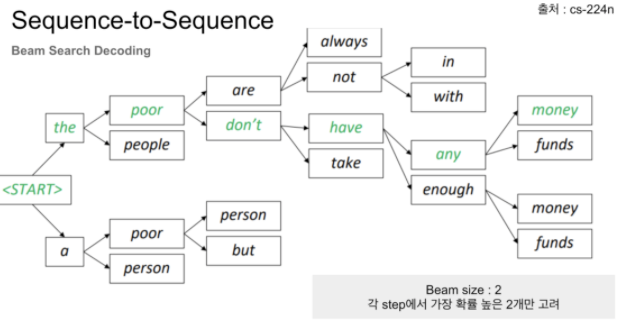
- 번역하는 길이가 길어지면 Penalty를 줌 : \( \alpha = 0.6 \)
- 조건부 확률의 최대화를 통하여, 최적의 번역 결과를 찾는 것
* 예시 : 매 순간의 최적의 번역 결과를 내놓는 것(Greedy Search) 보다,
복합적인 단어의 문맥을 고려한 번역 결과를 생성하는 게 번역 품질이 우수
- Beam Search란 : 각 Step에서 Beam Size 만큼을 함께 고려하면서,
최적의 조건부 확률을 가지는 문맥을 선정해 나아가는 방법
- Beam Size를 크게 하면, 번역 선능은 높아지나, 디코딩 속도가 저하됨
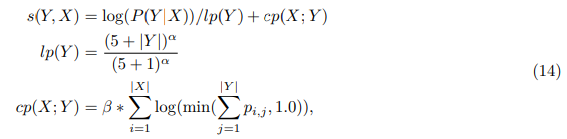
○ Model Variantions

• Model Averaging 사용 X
• Beam Search 사용 O
• (A) Multi-Head에 대한 고찰 : Single Head이나 너무 많은 Head는 성능이 저하됨
• (B) Attention의 Dimension에 대한 고찰 : \( d_{k} \)를 줄이면 품질이 저하됨
- Dot-Product Attention 보다 더 정교한 "Compatibility 함수"가 있을 수 있음을 시사
• (C) Model의 크기에 대한 고찰 : 더 큰 모델이 더 좋은 성능
• (D) 과적합에 대한 고찰 : 과적합 방지가 성능에 더 좋음
• (E) Learned Positional Embedding에 대한 고찰 : 성능이 거의 동일 → 고정된 Sinusoids 써도 됨
○ English 구문 분석 - Genalization
• 구문 분석을 통해, Transformer의 일반화(Genalization) 성능 확인
- 구문 분석은 Output이 Input 보다 더 길고, 구조적인 제약을 받음
• 새로운 Task에 대한 특별한 구조 변경 없이, 좋은 성능을 얻음
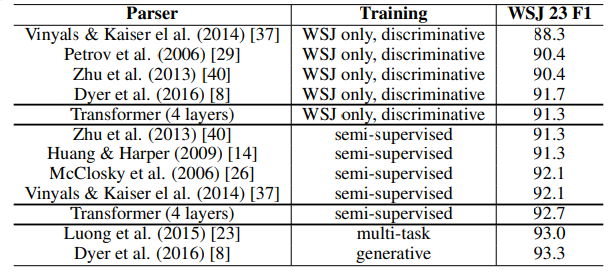
마치며
○ Transformer의 의의
• Multi-Head Self Attention 제안
- 엄청난 발견!
- Convolutional이나 Recurrent 보다 더 빠르게 학습할 수 있음
- 여러 분야에서 SOTA 달성 (심지어 Image Task에서도!)
• 코드 공개 : https://github.com/tensorflow/tensor2tensor
○ Transformer의 향후 과제
• Decoder에서 Sequential 한 과정을 축소하는 방법
• 큰 Input이나 Output을 어떻게 다룰 것인가(예를 들어, Audio, Video 같은 Task)
○ 논문 요약을 마치며
• 딥러닝 분야에서 반드시 읽어야만 하는 논문을 드디어 읽어서 다행이라고 생각합니다
• 생각보다 많은 디테일들이 있어서 큰 도움이 되었습니다
- 블로그뿐만 아니라 논문도 직접 꼭 읽어봐야 할 부분이 많네요
• 그래도, 중요한 논문인 만큼 많은 블로그에서 큰 도움을 받았습니다!! 감사합니다
'딥러닝을 위한 > 가이드(Guide)' 카테고리의 다른 글
| [논문요약] Transformer 등장 - Attention Is All You Need(2017) ① (4) | 2021.07.27 |
|---|---|
| [논문요약] Classification 학습방법 - Bag of Tricks(2018) (0) | 2021.04.01 |
| 딥러닝을 위한 논문 가이드 (8) | 2021.02.13 |